kottke.org posts about audio
The holes drilled into Arctic, Antarctic, and glacial ice to harvest ice cores can be up to 2 miles deep. One of my all-time favorite sounds is created by dropping ice down into one of these holes — it makes a super-cool pinging noise, as demonstrated in these two videos:
Ice makes similar sounds under other conditions, like if you skip rocks on a frozen lake:
Or skate on really thin ice (ok this might actually be my favorite sound, with apologies to the ice core holes):
Headphones are recommended for all of these videos. The explanation for this distinctive pinging sound, which sounds like a Star Wars blaster, has to do with how fast different sound frequencies move through the ice, as explained in this video:
(via the kid should see this)
Foley artist Richard Hinton talks about how he creates sounds for nature documentaries like Planet Earth. I love watching Foley artists do their thing, but I have mixed feelings about these made-up sounds!
Despite the veneer of neutrality of nature documentaries, I know there’s no such thing as objective truth when you’re dealing with cameras and film editing. And silent video is boring. But on the other hand, just making up sounds that spiders don’t actually make — I don’t know. I’ve posted about this before, regarding a video series about how Planet Earth II was made:
I hope the third program is on sound, which has been bugging me while watching Planet Earth II. I could be wrong, but they seem to be using extensive foley effects for the sounds the animals make — not their cries necessarily, but the sounds they make as they move. Once you notice, it feels deceptive.
See also How Fake Are Nature Documentaries?
Is it manipulation? Or good storytelling? And what’s the difference between the two anyway? A silent security feed of a Walmart parking lot is not a documentary but The Thin Blue Line, with its many dramatizations and Philip Glass score, is a great documentary.
(via open culture)
Linus Akesson noticed that without the benefit of the acoustical properties of massive churches, the sound that comes out of organ pipes sounds tinny, like 8-bit chiptune sounds.
Back in 2008 I had an epiphany about church organs: At least in theory, organ pipes produce very simple waveforms, much like 8-bit sound chips do-and the reason church organs don’t sound like chiptunes is primarily because of the acoustics of the church.
Thinking that process could be reversed, he remapped the keys of a Commodore 64 so he could play it like an accordion, ran it though a reverb machine, and created the sixtyforgan. The Bach piece he plays at the end of the video above (and a different Bach piece here) sounds so much like it’s being played on an organ.
See also Hear How Choral Music Sounded in the Hagia Sophia More Than 500 Years Ago (in which a filter is applied to choral music to make it sound as though it’s being sung in a cavernous church). (via @emanuelfeld)
If you’re anything like me and all you want to do today is watch some guys hand-ringing a giant bell, here you go. If we click play at the same time, we can watch it together. Ready? 3…2…1…go.
See also The Otherworldly Sounds of a Giant Gong. (via @MachinePix)

Tree.fm lets you tune into the sounds of different forests from around the world, bringing a taste of forest bathing to those who are staying at home, people in cities, or anyone else who needs to hear remote wild places. The sounds are taken from this crowdsourced forest soundmap that I featured a few months ago. Feature request: a “take me to another random forest in 10 minutes” button.
See also Gordon Hempton’s work and his recordings of forests and other wild places. (via kottke ride home)
I read both of the excerpts from A Promised Land, Barack Obama’s memoir of his time in the White House: I’m Not Yet Ready to Abandon the Possibility of America from The Atlantic and A President Looks Back on His Toughest Fight in the New Yorker. I have also been listening to the audiobook version, read by Obama himself, over the last few days and if you’re at all interested in this book, I would suggest going with the audiobook. Here’s an excerpt of Obama reading the preface (and several more of other parts of the book):
Not that there’s anything wrong with the written version, but the audiobook conveys more context and information. Much of the time, Obama writes like he talks, so listening to him read his own writing is like sitting across the dinner table from him as he tells you about how he became President. You can hear which parts of the book he really cares about and which parts are in there just to bridge gaps. He does impressions — of Desmond Tutu and his Kenyan relatives — and inflects words in other languages in the manner of Alex Trebek. He jokes around and gets serious. You can hear how frustrated he was, and continues to be, with Republican obstructionism. I’m only a few chapters in so far, but it will be interesting to hear his voice when he talks about the aspects of his Presidency that people believe didn’t live up to his lofty goals and visions. You really get the sense when listening to him that, unlike many politicians, he actually cares about helping people — or if you’re cynical, that he’s best-in-class at faking it; either way it’s fascinating to hear and make up your own mind.
You can listen to Obama read A Promised Land at Amazon or Libro.fm.
A site called Sounds of the Forest is collecting sounds from forests and woodland areas around the world and presenting them on a world map.
We are collecting the sounds of woodlands and forests from all around the world, creating a growing soundmap bringing together aural tones and textures from the world’s woodlands.
The sounds form an open source library, to be used by anyone to listen to and create from.
Here are a few of the sounds that they’ve collected.
See also the work of Gordon Hempton, who is trying to capture the sounds of the very few places left in the world without human noise. (via moss & fog)
Hi folks, I’ve got some exciting news today. The newest addition to kottke.org’s tiny media empire debuted yesterday: the Kottke Ride Home podcast. It’s a bloggy daily podcast featuring some of the day’s most interesting news and links in just 15 minutes, and you can subscribe to it on Apple Podcasts or wherever you listen to your podcasts (more options). The cool thing is that the podcast is very much its own thing with its own engaging host. It’s not a recap of the site in audio form, but instead is a whole different crop of news & information from the Kottke.org Media Universe (the KMU lol).
Here’s the first episode of Kottke Ride Home, featuring segments on the 100th anniversary of women’s suffrage in America, AI-assisted MRI scans that are up to 4X faster, and the “Lost Colony” of English settlers from 1587:
Ok, now that you’ve returned from subscribing, let me tell you about the show and how it came about.
I’ve been toying with the idea of doing a podcast for awhile now1 — they’re the hot thing, etc. — but I could never get myself interested enough to make it happen as a host/interviewer. But I know a lot of you love podcasts, so the notion remained simmering on a back burner. Knowing of these podcast aspirations, my pal Brian McCullough recently approached me about collaborating on a podcast.
Brian is a fellow old school internet person, host of the Internet History Podcast (for which he interviewed me in 2018), and author of the 2018 book, How the Internet Happened: From Netscape to the iPhone. He’s now running a podcast startup called Ride Home Media that’s focused on delivering short daily news podcasts about a variety of different subjects — some of you might be familiar with their flagship podcast TechMeme Ride Home, which they’ve been publishing since March 2018. Brian told me a podcast version of kottke.org has been on his bucket list for quite awhile, so that’s what we’re doing.
Kottke Ride Home is hosted & curated by writer/speaker/YouTuber Jackson Bird, whose TED Talk How to talk (and listen) to transgender people has been viewed more than 1.6 million times. For the past few months, Jackson’s been hosting Good News Ride Home — “In just 15 minutes, the coolest stuff that happened in the world today. Science, progress, life-hacks, memes, exciting art and hope.” — which will seamlessly shift into Kottke Ride Home with nary a disruption to what he’s already been doing.1 I’ve been listening to the show for the past few weeks and am excited to partner with Jackson to bring the best of the internet to you.
The podcast and the site will operate independently from each other but will obviously cover the same sorts of things. Like I said above, the show won’t be a recap of kottke.org posts; it’s designed to complement the site, to scratch that kottke.org itch when you’re in podcast-listening mode. But like when the Jeffersons showed up on the Fresh Prince of Bel-Air, there will undoubtably be things that make their way from the podcast to the site and vice versa.
Ok, that’s the skinny. You’ll be hearing more from me about the show in the coming days, but for now, check out Kottke Ride Home wherever you listen to podcasts.
P.S. Since it’s a new show — or rather a show with a new name — it will take some time for the name and artwork to propagate across the various podcast networks. You can find the show on the major services/apps using the subscribe button here, but here are some direct links: Apple Podcasts, Spotify, Google Podcasts, RSS, Overcast, Castro, Pocket Casts, and Luminary.
Researchers have demonstrated that they can make a working 3D-printed copy of a key just by listening to how the key sounds when inserted into a lock. And you don’t need a fancy mic — a smartphone or smart doorbell will do nicely if you can get it close enough to the lock.
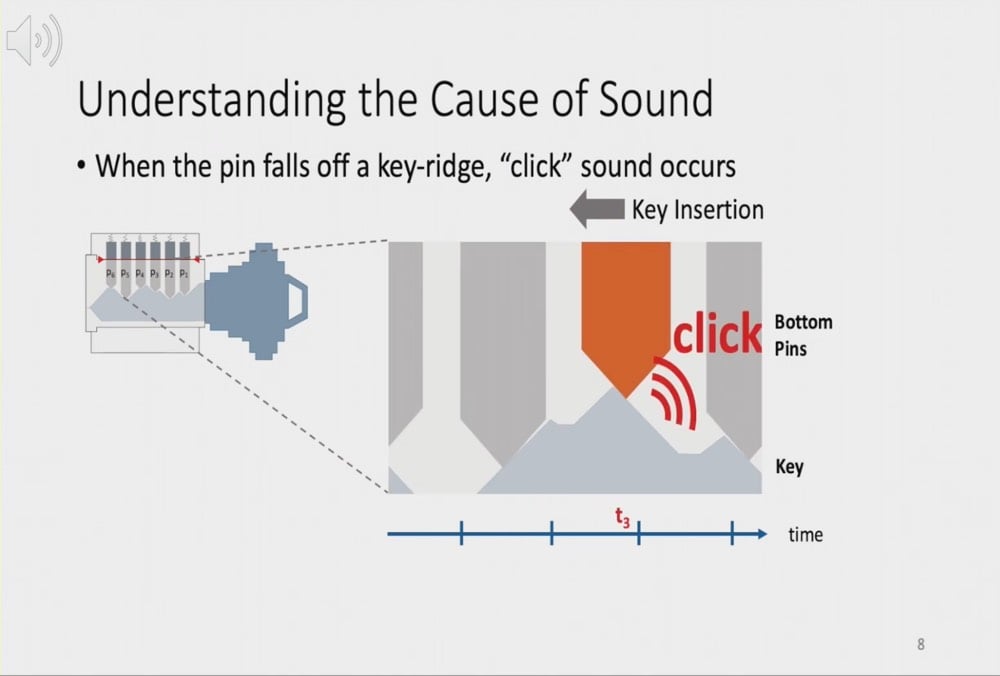
The next time you unlock your front door, it might be worth trying to insert your key as quietly as possible; researchers have discovered that the sound of your key being inserted into the lock gives attackers all they need to make a working copy of your front door key.
It sounds unlikely, but security researchers say they have proven that the series of audible, metallic clicks made as a key penetrates a lock can now be deciphered by signal processing software to reveal the precise shape of the sequence of ridges on the key’s shaft. Knowing this (the actual cut of your key), a working copy of it can then be three-dimensionally (3D) printed.
How Soundarya Ramesh and her team accomplished this is a fascinating read.
Once they have a key-insertion audio file, SpiKey’s inference software gets to work filtering the signal to reveal the strong, metallic clicks as key ridges hit the lock’s pins [and you can hear those filtered clicks online here]. These clicks are vital to the inference analysis: the time between them allows the SpiKey software to compute the key’s inter-ridge distances and what locksmiths call the “bitting depth” of those ridges: basically, how deeply they cut into the key shaft, or where they plateau out. If a key is inserted at a nonconstant speed, the analysis can be ruined, but the software can compensate for small speed variations.
The result of all this is that SpiKey software outputs the three most likely key designs that will fit the lock used in the audio file, reducing the potential search space from 330,000 keys to just three. “Given that the profile of the key is publicly available for commonly used [pin-tumbler lock] keys, we can 3D-print the keys for the inferred bitting codes, one of which will unlock the door,” says Ramesh.
Here’s Ramesh presenting her research at a conference back in March.
This reminded me of a couple of things. If you have a photo of a key, you can make a copy of it. And if you record high speed video of objects like plants or potato chip bags, you can use the observed vibrations to reconstruct the sound near those objects. All these secrets lying out in the open, just waiting for clever technologies to hoover them up. (via @nicolatwilley)
I love things that sound like other things and this video of a kid crashing into some trash bins on his bike sounds a lot like the drums in Phil Collins’ “In the Air Tonight”. (If I may play spoiler for just a second though, capturing the sound of those bins going over so clearly from that far away seems a little suspect. But let’s assume it’s real and have our fun.) See also This Stumbling Deer’s Hooves Sound Like Phil Collins’ Drum Fill on “In the Air Tonight”. (thx to everyone who sent this in)
In this hauntingly beautiful video, Jonna Jinton performs an ancient Nordic herding call called kulning to summon a herd of cows.
The herds grazed during the daytime, wandering far from the cottages, and thus needed to be called in each night. Women developed kulning to amplify the power of their voices across the mountainous landscape, resulting in an eerie cry loud enough to lure livestock from their grazing grounds.
One should always take caution when hanging out with someone kulning, as it can’t be done quietly. Rosenberg, who’s researched the volume of kulning, says it can reach up to 125 decibels — which, she warns, is dangerously loud for someone standing next to the source. Comparable to the pitch and volume of a dramatic soprano singing forte, kulning can be heard by an errant cow over five kilometers away.
(via moss & fog)
The NYPL has released an album of sound-based experiences that you might be missing right now as we all shelter at home: Missing Sounds of New York.
It’s a short album (16 min) and includes soundscapes like Serenity Is a Rowdy City Park, I’d Call a Cab to Anywhere, and The Not-Quite-Quiet Library.
See also this 3+ hour album of ambient city sounds. There are also many videos of ambient city sounds on YouTube, like this 10-hour video of ambient NYC sounds:
This is a mix of ambience sounds recorded around Christmas Eve as well as St Patrick’s Day. Enjoy the sounds of people talking, traffic noises, police sirens, subway sounds, footsteps around NYC. City sounds at night and day.
Or perhaps you’d like to go for a stroll in the city instead? (via the morning news)
This is fantastic: former beatboxing world champion Butterscotch explains the 13 levels of complexity involved in beatboxing, from the simple “bass drum” to how to breathe while beatboxing to singing to emulating real instruments.
Expert beatboxers go so fast that it’s amazing to see someone with Butterscotch’s skill level break this down — like watching a water balloon bursting in slow motion. Her short explanation & demonstration of “breathing within the beat” bleeeewww my tiny little mind. Also, she is soooo good — what a treat to watch.
See also Robert Lang on the 11 Levels of Complexity of Origami, Tony Hawk on the 21 Levels of Complexity of Skateboard Tricks, and A Demonstration of 16 Levels of Piano Playing Complexity.
Update: Phil Guillory is a speech-language pathologist and he wrote up a technical analysis of Butterscotch’s explanation of beatboxing. It is gloriously nerdy and I love it.
Humming adds a really interesting layer to this. The act of humming itself is a natural nasal sound. The soft palate, or velum, is relaxed, allowing airflow into the nasal passages. Humming requires glottic closure in order to vibrate vocal folds, and those vibrations resonate up the oropharynx and, because the lips are closed, the air then has to travel into the nasopharynx to be released. When Butterscotch adds percussive beats on top of the hum, if there truly is nasal airflow, that would mean that her velum isn’t fully contacting the pharyngeal wall, and there would be a combination of nasal and pharyngeal air flow. Obviously, a video like this won’t allow us to visualize, so we’ll have to make a couple of assumptions here: a combination of oral and nasal airflow would (1) reduce the loudness of the beats while (2) also reducing the loudness of the hum itself. This is because air would be traveling in two directions, so there would be less pressure for both, and thus, less loudness and resonance. Given that the hum sounds pretty consistent, I think it’s safe to guess that Butterscotch is able to relax her velum to allow for nasal airflow voluntarily, which is indeed a very challenging thing to do given that velar movement is largely automatic. Super cool.

Sound artist & designer Yuri Suzuki has designed the Easy Record Maker, an affordable machine for cutting your own records. Suzuki explains how it works on Instagram:
To cut a record, you simply play audio through an aux cable and lift the cutting arm onto a blank disc. Once the record is cut, you can instantly play back your recording through the tone arm and the in built speaker!
More like cute your own records — look at how wee this thing is:

It’s out now in Japan and will be released in the US & UK later in the year. The price seems to be in the $80-100 range. Read more about the Easy Record Maker at Design Week. (via boing boing)
When the Ottomans invaded and conquered Constantinople in 1453, the Orthodox Christian church Hagia Sophia was converted into a mosque. As a result, the Christian choral music that had reverberated in this acoustical masterpiece for centuries was not allowed. But thanks to a digital filter developed by a pair of Stanford researchers, one an art historian (Bissera Pentcheva) and the other an acoustics expert (Jonathan Abel), we are now able to hear what a choir might have sounded like in the Hagia Sophia before the mid 15th century.
When they met, Pentcheva started telling Abel about the Hagia Sophia — how we couldn’t really understand the experience of worshipers there unless we could hear the music the way they did. And as she talked, Abel started to feel a prickling of excitement. They could recreate what that music would sound like. If only they could get in the Hagia Sophia and pop a balloon.
When a balloon pops, it makes an impulse, a sharp, quick sound that takes on the character of whatever space it’s in. So when a balloon pops, you’re really hearing the acoustics of the space itself, says Abel.
In this clip from 2013, the Cappella Romana choir sings a hymn passed through an early version of the Hagia Sophia filter:
The marble interior of Hagia Sophia was 70 meters long, while in height it reached 56 meters at the apex of the great dome. The vast chamber and its reflective surfaces of marble and gold resulted in unprecedented acoustics of over ten seconds reverberation time. As a museum Hagia Sophia today has lost its voice, no performances could take place in it. Using new digital technology developed at CCRMA, the second portion of Cappella Romana’s concert at Bing aims to recreate sound of what singing in Hagia Sophia must have been like. Each singer caries a microphone that records the sound transforming it into a digital signal, which is then imprinted with the reverberant response of Hagia Sophia. What you hear as a wet sound is the product of a digitally produced signal transmitted through loudspeakers placed strategically to create an enveloping soundfield. This digital signal may shock you with the way it relativizes speech, transforming its content into a chiaroscuro of indistinct but immersive sound. For the Byzantines, this sonic experience was associated with the water: the waves of the sea.
Last year, the Cappella Romana released an entire album of choral music recorded with the filter — you can listen on Spotify, Apple Music, Amazon, Tidal, or Pandora.
Needless to say, the album sounds better with the best pair of headphones you can muster. You can find out more information about the filter and the acoustics of the Hagia Sophia at Icons of Sound.
See also this online Gregorian chant generator.
I love echo - any kind of reverberation or atmosphere around a voice or a sound effect that tells you something about the space you are in.
That’s a quote from legendary film editor and sound designer Walter Murch. In the 70s, he pioneered a technique called worldizing, for which he used a mix of pristine studio-recorded and rougher set-recorded sounds to make a more immersive soundscape for theater audiences. He used it in The Godfather, Apocalypse Now, and American Graffiti:
George [Lucas] and I took the master track of the two-hour radio show with Wolfman Jack as DJ and played it back on a Nagra in a real space — a suburban backyard. I was fifty-or-so-feet away with a microphone recording that sound onto another Nagra, keeping it in sync and moving the microphone kind of at random, back and forth, as George moved the speaker through 180 degrees. There were times when microphone and speaker were pointed right at each other, and there were other times when they were pointed in completely opposite directions. So that was a separate track. Then, we did that whole thing again.
When I was mixing the film, I had three tracks to draw from. One of them was what you might call the “dry studio track” of the radio show, where the music was very clear and sharp and everything was in audio focus. Then there were the other two tracks which were staggered a couple of frames to each other, and on which the axis of the microphone and the speakers was never the same because we couldn’t remember what we had done intentionally.
I am fascinated with the sound of movies, from the soundtracks to the foley effects and even temp music. Making Waves is a documentary about this integral aspect of cinema. Here’s a trailer:
Directed by veteran Hollywood sound editor Midge Costin, the film reveals the hidden power of sound in cinema, introduces us to the unsung heroes who create it, and features insights from legendary directors with whom they collaborate.
Featuring the insights and stories of iconic directors such as George Lucas, Steven Spielberg, David Lynch, Barbra Streisand, Ang Lee, Sofia Coppola and Ryan Coogler, working with sound design pioneers — Walter Murch, Ben Burtt and Gary Rydstrom — and the many women and men who followed in their footsteps.
(thx, dunstan)
This morning, instead of crawling straight from bed to desk and diving into the internet cesspool, I went for a walk. I went because I needed the exercise, because it was a nice sunny day out, because the changing leaves are super lovely right now. (Check out my Instagram story for some of what I saw along the way.) But I also wanted to listen to this episode of On Being with Gordon Hempton called Silence and the Presence of Everything. Hempton is an acoustic ecologist who has a lot of interesting things to say about silence and natural sounds.
Oh, grass wind. Oh, that is absolutely gorgeous, grass wind and pine wind. We can go back to the writings of John Muir, which — he turned me on to the fact that the tone, the pitch, of the wind is a function of the length of the needle or the blade of grass. So the shorter the needle on the pine, the higher the pitch; the longer, the lower the pitch. There are all kinds of things like that, but the two folders where I collected, I have, oh, over 100 different recordings which are actually silent from places, and you cannot discern a sense of space, but you can discern a sense of tonal quality, that there is a fundamental frequency for each habitat.
It sounds paradoxical, but I wanted to listen to this podcast in a setting with natural sounds, rather than in my car or on a plane. I had my AirPods in because they don’t block all outside sound, so I could hear the crunch of the road beneath my shoes as I walked and listened. The nature and animal sounds in the episode sounded like they were actually coming from all around me. I paused the episode for a minute or two to listen to a burbling brook I passed along the way. The whole experience was super relaxing and informative.1
You can read more about Hempton and his efforts in preserving the world’s silence places on his website The Sound Tracker or in his book, One Square Inch of Silence. Outside magazine recently profiled Hempton, who, in cruel twist of fate, has suffered dramatic hearing loss in recent years.
The problem Hempton hopes to take on is gargantuan. To understand it, try a little experiment: when you reach the period at the end of this sentence, stop reading for a moment, close your eyes, and listen.
What did you hear? The churn of the refrigerator? The racing hiss of passing traffic? Even if you’re sitting outside, chances are you heard the low hum of a plane passing overhead or an 18-wheeler’s air horn shrieking down a not-so-distant highway.
If you heard only the sounds of birds and the wind in the trees, you’re one of a lucky few. But it’s likely that quiet won’t last.
This short documentary, Sanctuaries of Silence, follows Hempton to some of the quietest places on Earth, including the Hoh Rain Forest in Olympic National Park.
I think what I like most about listening is that I disappear.
If you’d like to disappear for awhile but don’t have access to a quiet place, you should check out some of Hempton’s recordings on Spotify — I’m listening to Forest Rain right now.
Or try out the Sound Escapes podcast to check out some of his best natural soundscapes. (thx Meg, who sent along a link to the On Being episode after reading yesterday’s post on noise pollution)
For The Atlantic, Bianca Bosker writes about the growing problem of noise pollution (because of our love of technology and hands-off governments) and why so few people take it seriously (because of our love of technology and hands-off governments).
Scientists have known for decades that noise — even at the seemingly innocuous volume of car traffic — is bad for us. “Calling noise a nuisance is like calling smog an inconvenience,” former U.S. Surgeon General William Stewart said in 1978. In the years since, numerous studies have only underscored his assertion that noise “must be considered a hazard to the health of people everywhere.” Say you’re trying to fall asleep. You may think you’ve tuned out the grumble of trucks downshifting outside, but your body has not: Your adrenal glands are pumping stress hormones, your blood pressure and heart rate are rising, your digestion is slowing down. Your brain continues to process sounds while you snooze, and your blood pressure spikes in response to clatter as low as 33 decibels-slightly louder than a purring cat.
Experts say your body does not adapt to noise. Large-scale studies show that if the din keeps up-over days, months, years-noise exposure increases your risk of high blood pressure, coronary heart disease, and heart attacks, as well as strokes, diabetes, dementia, and depression. Children suffer not only physically-18 months after a new airport opened in Munich, the blood pressure and stress-hormone levels of neighboring children soared-but also behaviorally and cognitively. A landmark study published in 1975 found that the reading scores of sixth graders whose classroom faced a clattering subway track lagged nearly a year behind those of students in quieter classrooms-a difference that disappeared once soundproofing materials were installed. Noise might also make us mean: A 1969 study suggested that test subjects exposed to noise, even the gentle fuzz of white noise, become more aggressive and more eager to zap fellow subjects with electric shocks.
Being pretty sensitive to noise, I read this piece with a great deal of interest. One of the benefits of living in the middle of nowhere in the country is that when I go outside, the sounds I hear are mostly natural: birds, streams, wind, frogs, and insects. In the winter, the quiet is sometimes so complete that you can only hear the sound of your own heart beating in your ears. But lately, some dipshit who owns a car with a deliberately loud after-market muffler has been driving through the surrounding hills, disrupting the peace. I can’t usually hear cars passing on the nearby road, but this muffler jackass you can hear literally miles away. It makes me want to smash things! I feel like a bit of a crank, but why does this person’s freedom to have a loud muffler override the freedom of the thousands of people within earshot to have quiet? (See also positive versus negative liberty and How Motorcyclists Think People React When They Drive By.)
BBC Radio 4 has done an abridged audio reading of Margaret Atwood’s The Testaments, her followup to The Handmaid’s Tale. The series is composed of 15 episodes that run 14 minutes each — a total of 3.5 hours compared to the full 13+ hour audiobook. The episodes are only going to be available online for a short time though — the first one expires Oct 15 — so get in there if you’re going to listen. I’m reading the book right now, otherwise I’d be right there with you. (via open culture)

Yellowstone National Park maintains a collection of sounds and videos taken in the park that are in the public domain and free for anyone to use. The collection includes the sights and sounds of birds, geysers, bison, bubbling mud pots, fish, wolves, falling snow, storms, and all sorts of other ambient noises and videos.
For Real Life magazine, Drew Austin writes about wireless headphones and their potential effect on the public sphere if many people start wearing them. The bit that particularly caught my eye was the subtitle of the piece:
Wireless headphones are augmented reality devices.
And further down the page:
Much as phones have enabled and concretized the always-on nature of everyday life, introducing the constant interpenetration of physical and digital space to individual experience, wireless earbuds facilitate a deeper integration, an “always in” existence that we need never interrupt by looking down at a screen. Their aural interface means we don’t have to awkwardly switch attention back and forth between IRL and a screen as though the two are starkly separated. Instead, we can seem to occupy both seamlessly, an experience that other augmented-reality devices, like Google Glass, have promised with varying degrees of success.
I bought some AirPods several months ago thinking I was getting wireless headphones, but very quickly realized they were actually an augmented-reality wearable computer. In my media diet post from May, I called them “the first real VR/AR device that feels seamless”. Like regular wired earbuds or even over-the-ear Bluetooth headphones, AirPods provide an audio track layered over the real world, but they’re so light and let just the right amount of ambient sound in that you barely notice you’re wearing them — it just sounds like whatever you’re listening to is playing in your head, automagically. It feels, at least to me, like a totally different and far more immersive experience. Wearable computing still seems like a futuristic thing a few years away, but with AirPods and the Apple Watch, it’s solidly here right now.
P.S. In Dan Hon’s latest newsletter, he writes:
Given current phone/camera trends (or, I should say, current camera/phone trends), the Star Trek: TNG combadge is unrealistic because by the 24th century it’d be more like 99.9998% camera and 0.0002% phone.
The natural ancestor of the combadge seems more like AirPods than the iPhone. But the likelihood of AirPods 6.0 having a tiny camera embedded in it for, say, the facial recognition of whoever you’re speaking with (a la Miranda Priestly’s assistants in The Devil Wears Prada) or text-to-speech for whatever you’re looking at (signs, books, menus) seems quite high.
YouTuber Lord Vinheteiro recently played the same pair of tunes on six different pianos, ranging from a $499 used upright to a $112,000 Steinway to a $2.5 million Steinway grand piano that’s tacky af. Which one sounds the best?
I’m not sure that you get the full effect and nuance of the super luxe pianos after the audio has passed through YouTube’s audio compression and whatever phone or computer speaker or headphones you’ve got going, but the more expensive pianos sound better than the lower-end ones for sure. I would have appreciated a medley at the end that repeatedly cycled through all six of the recordings to better hear the differences.
From a 1972 episode of Mister Rogers’ Neighborhood, Mister Rogers demonstrates how to make a record using a machine called a record cutter (also referred to as a “record lathe”). Says Rogers, apparently living his best life: “When I was a little boy, I thought the greatest thing in the world would be to be able to make records.” (via open culture)
The Apollo Flight Journal has put together a 20-minute video of the full descent and landing of the Apollo 11 Lunar Module containing Neil Armstrong and Buzz Aldrin on July 20, 1969.
The video combines data from the onboard computer for altitude and pitch angle, 16mm film that was shot throughout the descent at 6 frames per second. The audio recording is from two sources. The air/ground transmissions are on the left stereo channel and the mission control flight director loop is on the right channel. Subtitles are included to aid comprehension.
Reminder that you can follow along in sync with the entire Apollo 11 mission right up until their splashdown. I am also doing my presentation of Walter Cronkite’s CBS news coverage of the landing and the Moon walk again this year, starting at 4:10pm EDT on Saturday, July 20. Here’s the post I wrote about it last year for more details. (thx, david)
I don’t know who needs to hear this, but if you’re in need of some relaxing sounds, a meditative moment, or a chill work soundtrack, I recommend this 71-minute video of Tibetan singing bowl music.
See also Hours and Hours of Relaxing & Meditative Videos.
Listen in as “Gong Master Sven” plays a gong that’s 7 feet across. (No seriously, listen…it’s wild. Headphones recommended.)
Ok, show of hands. How many of you of thought it was going to sound like that? I had no idea! He barely hits it! The whole thing sounded like a horror movie soundtrack or slowed-down pop songs. Here’s another demonstration, with some slightly harder hits:
The Memphis Gong Chamber looks like an amazing place. Watching this on YouTube, we’re missing out on a lot of the low-end sounds:
And if you were actually standing here like I am, you can feel all your internal organs being massaged by the vibrations from this. It’s really quite the experience.
This guy drags some objects over a large gong and it sounds like whale song:
Ok well, there’s a new item for the bucket list. (via @tedgioia)
The National Sound Library of Mexico says they have found the only known audio recording of Frida Kahlo’s voice. Take a listen:
The library have unearthed what they believe could be the first known voice recording of Kahlo, taken from a pilot episode of 1955 radio show El Bachiller, which aired after her death in 1954.
The episode featured a profile of Kahlo’s artist husband Diego Rivera. In it, she reads from her essay Portrait of Diego, which was taken from the catalogue of a 1949 exhibition at the Palace of Fine Arts, celebrating 50 years of Rivera’s work.
“He is a gigantic, immense child, with a friendly face and a sad gaze,” she says, as translated by Agence France-Presse. (A different English translation of the text can be found on Google Arts & Culture.)
Film footage of Kahlo is difficult to come by as well; I could only find these two clips:
The first video is in color and shows Kahlo and husband Diego Rivera in her house in Mexico City. The second shows Kahlo painting, drawing, and socializing with the likes of Leon Trotsky. At ~0:56, she walks quickly and confidently down the stairs of a ship, which is a bit surprising given what I’ve read about her health problems.
Update: According to this article (and its translation by Google), the voice on the recording isn’t Kahlo but belongs instead to actress Amparo Garrido:
Yes, I recognize myself. For me it was a big surprise because so many years had passed that I really did not even remember. […] When listening to this audio I remembered some things and I got excited because I did recognize myself.
(via @p_tricio)
The National Oceanic and Atmospheric Administration (NOAA) and Google have teamed up on a project to identify the songs of humpback whales from thousands of hours of audio using AI. The AI proved to be quite good at detecting whale sounds and the team has put the files online for people to listen to at Pattern Radio: Whale Songs. Here’s a video about the project:
You can literally browse through more than a year’s worth of underwater recordings as fast as you can swipe and scroll. You can zoom all the way in to see individual sounds — not only humpback calls, but ships, fish and even unknown noises. And you can zoom all the way out to see months of sound at a time. An AI heat map guides you to where the whale calls most likely are, while highlight bars help you see repetitions and patterns of the sounds within the songs.
The audio interface is cool — you can zoom in and out of the audio wave patterns to see the different rhythms of communication. I’ve had the audio playing in the background for the past hour while I’ve been working…very relaxing.
LJ Rich has synesthesia and perfect pitch and wrote about what that feels like for her personally.
Now, I’d like you to imagine you’re chatting with your conversation partner. But instead of speaking and hearing the words alone, each syllable they utter has a note, sometimes more than one. They speak in tunes and I can sing back their melody. Once I know them a little bit, I can play along to their words as they speak them, accompanying them on the piano as if they’re singing an operatic recitative. They drop a glass on the floor, it plays a particular melody as it hits the tiles. I’ll play that melody back — on a piano, on anything. I can accompany that melody with harmony, chords — or perhaps compose a variation on that melody - develop it into a stupendous symphony filled with strings, or play it back in the style of Chopin, Debussy or Bob Marley. That car horn beeps an F major chord, this kettle’s in A flat, some bedside lights get thrown out because they are out of tune with other appliances. I can play along to every song on the radio whether or not I’ve heard it before, the chord progressions as open to me as if I had the sheet music in front of me. I can play other songs with the same chords and fit them with the song being played. Those bath taps squeak in E, this person sneezes in E flat. That printer’s in D mostly. The microwave is in the same key as the washing machine.
I have a friend with perfect pitch and one of the first times we hung out together, the horn on a tugboat sounded and she said, “C sharp”. I looked puzzled so she explained, and then I peppered her with questions about all the other sounds around us. It was like watching a superhero do their thing.
But with great power sometimes comes great irritation. From a NY Times article about Rich:
LJ said she had been a “weird prodigy kid.” For her, perfect pitch had been a nightmare. The whole world seemed out of tune. But then teachers introduced her to Indian ragas, Gamelan music and compositions with quarter tones, unfamiliar modes and atonal structures. As her musical horizons expanded, her anxiety dissipated. (She remains exceedingly sensitive to pitch, though. Her refrigerator, for example, hums in A flat. Working from home, I hear my fridge running 12 hours a day. Blindfolded, I’m not sure I could pick the thing out of a lineup of three other refrigerators.)
Newer posts
Older posts
Socials & More