kottke.org posts about artificial intelligence
Matthew Butterick is a lawyer, programmer, writer, and designer. He’s written a long, interesting piece about the inherent risks of AI called Extinction-Level Capitalism. It is well-worth a read; I’ve excerpted several passages here but urge you read the whole thing.
In practice, certain people in a capitalist liberal democracy tend to get increasingly rich. Absent countermeasures, the wealthy gain control of the political apparatus, thwarting liberal-democratic norms. This tension between capital and politics is a long-considered topic. A key early work was, of course, Karl Marx’s Capital (about which more later). In the current era, Mancur Olson’s book The Rise and Decline of Nations set out how small groups with a shared interest (which could include capital concentration) can effectively undermine stable societies. More recently, economists Robert Reich (“How Capitalism is Killing Democracy”), James Galbraith (The Predator State), and Yanis Varoufakis (Technofeudalism: What Killed Capitalism) are among those who have studied the escalating political consequences of rising wealth inequality. The synthesis might be: as more wealth becomes concentrated in the hands of fewer citizens, liberal democracy weakens, because whichever citizens are losing economic relevance will also lose political relevance. A nation sending many of its citizens toward economic irrelevance risks becoming politically illiberal.
Sci-fi plots are optimized for cinematic impact. So as a metaphor for AI risk, they can lead to faulty intuitions. Among realistic AI risks, we can expect that most will be boring, slow, and depend on minimal extra technology. Whether AI will cause literal human extinction is esoteric—a lightning strike. But AI could easily induce future economic and political conditions that most Americans today would consider intolerable—a cancer that extinguishes a certain way of life. Nobody’s going to make a movie about boring AI risks. But they comprise the majority of worrisome AI outcomes.
Marx’s observation has a subtler implication too. New technology often holds itself out as the starting point of a narrative: from now on, everything is different. When we consider the technology alone, that narrative dominates. But when we zoom out and consider the historical context, the new technology becomes the current endpoint of a much longer political narrative.
What would Marx say to AI critics—social, legal, economic, political—that have arisen so far? Maybe that we’re missing the bigger picture. That as a human invention, AI may be the starting point of a new technological narrative. But as an affront to human workers, it continues a long tradition of capitalist technologies, beginning with the Industrial Revolution (if not earlier).
When we think about AI risk, we’re necessarily making guesses about the future. But when we frame AI in the narrow sense of new technology, we’re primarily considering a timeline that starts now. Whereas when we shift to thinking of AI as a capitalist instrument, we’re considering a timeline that starts centuries ago and has evolved continuously into the present. We can and should study those existing economic and political trends, because those will likely shape the future trajectory. Put differently: AI may be new. But it’s not immune to history.
“Technology always makes certain jobs obsolete; new ones will arise.” AI’s predicted labor replacement is unprecedented in three ways: the diversity of tasks replaced; its outsize effect on highly educated workers; and the backdrop of 50 years of wage stagnation. Automation-driven transitions aren’t necessarily easy, even when they’re narrow and the economy can absorb the workers. Those who handwave over the details should study historical examples. When you tell a large group of workers that their skills no longer have economic value, you risk a political and social tinderbox. Recall Carl Benedikt Frey’s comment: “the short run can be a lifetime”.
Along these lines, I expect that to succeed financially, Big AI will likely need to demolish a significant number of existing tech companies and grab their revenue for itself. By the process described above: Big AI essentially uses its tech customers as an R&D facility. Big AI licenses models to these companies. Tech companies compete to adapt their businesses to AI. Once a concept is proven, Big AI directly takes over that market. The labor-replacement story will grow into a company-replacement story. Many of those tech companies—and their shareholders in the public markets—may also find that AI is a poisoned chalice.
The value of the concentrated resource creates what Jeffrey Frankel calls “a political contest to capture ownership”, which in turn encourages the emergence of autocratic or oligarchic institutions captured by an economic elite who seek to retain control of the resource. The process is self-reinforcing in two ways. First: the economic elite uses its wealth to repress political opponents. Second: as the government derives more income from the concentrated resource, it relies less on taxation of citizens, which weakens democratic accountability.
I could have easily excerpted the whole thing.
Charity Majors, writing about how high-performing engineering teams are dealing with the transition from pre-AI to AI-native development: AI enthusiasts are in a race against time, AI skeptics are in a race against entropy.
This is not a situation where one side is right and the other is huffing paint. (O, that it were!) Each side is grappling with a real, alarming, escalating threat to the company’s existence, and the closer they look the more (again: real, alarming) evidence they find.
The enthusiasts are not wrong. We are starting to see real, non-imaginary, discontinuous leaps in capabilities from teams that lean in hard to working with AI. And this does not feel like a normal technology cycle where you can wait for the dust to settle; teams that sit this out while competitors are hustling could be out of business before the dust settles. That’s a real, existential threat.
The skeptics are also not wrong. When you ship code faster than engineers can read it, in domains where nobody has full context, you are making withdrawals from a trust account that took years to build. Reliability degrades, institutional knowledge evaporates. You end up with systems nobody understands, products burbling into incoherence, and on-call rotations that grind people up and spit them out. That is ALSO a real existential threat.
She goes on to say that “the wins and costs are happening to two different groups of people. There is no natural feedback loop.” Interesting read.
Pope Leo XIV released his first encyclical letter yesterday; it’s entitled Magnifica Humanitas Of His Holiness Pope Leo XIV On Safeguarding the Human Person In the Time of Artificial Intelligence. It is very long and I haven’t been able to read the whole thing; here’s a taste:
It is not possible to provide a single, comprehensive definition of AI. What can be stated, however, is that we must avoid the misconception of equating this type of “intelligence” with that of human beings. These systems merely imitate certain functions of human intelligence. In doing so, they often surpass human intelligence in speed and computational capacity, offering tangible benefits across many fields. Yet this power remains entirely tied to data processing. So-called artificial intelligences do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships and do not know from within what love, work, friendship or responsibility mean. Nor do they have a moral conscience, since they do not judge good and evil, grasp the ultimate meaning of situations, or bear responsibility for consequences. They may imitate language, behavior and analytical skills, or even simulate empathy and understanding, but they do not understand what they produce, for they lack the affective, relational and spiritual perspective through which human beings grow in wisdom. Even when these tools are described as capable of “learning,” their way of doing so is different from that of a human person. It is not the experience of those who allow themselves to be shaped by life and grow over time through choices, mistakes, forgiveness and fidelity. Rather, it is a form of statistical adaptation based on data and feedback, which can be very effective, but does not imply inner growth.
You can replace “AI”, “tools”, and “systems” in that paragraph with “a certain sort of amoral tech billionaire like Musk, Andreessen, and Thiel” or “a data-driven business focused solely on maximizing shareholder value” and it’s no less true. (“It’s just business.”)
Simon Willison’s notes on the encyclical are interesting; he calls it “some of the clearest writing I’ve seen on the ethics of integrating AI into modern society”. I noted this part as well while skimming through:
For individuals as well as for nations, development is both a duty and a right. Minimum conditions are required for enabling every person and people to flourish in accord with their dignity, without being kept in a state of dependence or excluded from access to necessary goods. Development is truly human when it places people at the center instead of the accumulation of wealth, and when it concerns peoples as well as individuals. Justice demands the recognition of the rights of society and the rights of peoples, and includes a responsibility toward future generations. Development is not truly human if it increases consumption for some while shifting costs and burdens onto others, or relegates entire regions to subordinate roles, preventing them from realizing their full potential.
And:
The use of AI is never a purely technical matter: when it enters processes that affect people’s lives, it touches on rights, opportunities, status and freedom. Important and sensitive decisions — concerning employment, credit, access to public services or even a person’s reputation — risk being fully delegated to automated systems that do not know “compassion, mercy, forgiveness, and above all, the hope that people are able to change,” and can therefore give rise to new forms of exclusion.
The Catholic Church is the Catholic Church, but plain language with some real thought and tradition behind it is welcome in the AI discussion. As Tim Carmody says:
I’ve said it before but it’s something else to watch a gifted author (with a team of talented researchers) discuss AI with the weight of a 2000-year intellectual and moral tradition behind them, both reckoning with that tradition and trying to project far into the future. Very different from “how will this affect Nvidia’s stock price”.
And Chris Xu:
Skimmed the encyclical and was repeatedly struck by how shocking (good) it feels to read a coherent institutional vision / strategy for how to maneuver through These Times rooted in common sense and firm principles. We have been intellectually failed and starved by so many other institutions.
You can read the whole thing in English (and nine other languages) on the Holy See’s website or read a summary.
Interesting observation by Mitchell Hashimoto (creator of Vagrant and Ghostty) on how a company’s or product’s choice of programming language matters less in the age of agentic programming:
On the interesting side is how fungible programming languages are nowadays. Programming languages used to be LOCK IN, and they’re increasingly not so. You think the Bun rewrite in Rust is good for Rust? Bun has shown they can be in probably any language they want in roughly a week or two. Rust is expendable. It’s useful until it’s not then it can be thrown out. That’s interesting!
Hashimoto is talking about this complete rewrite of Bun (a Javascript/Typescript toolkit that’s owned by Anthropic and includes “a fast JavaScript runtime designed as a drop-in replacement for Node.js”) in a completely different programming language (Rust) in just 6 days.
6,755 commits, branch name claude/phase-a-port, PR opened May 8th, merged May 14th.
Six days. A full rewrite of a production-grade JS runtime, merged in six days.
Let that number sit in your mind for a second.
Whether or not you think that taking this six-day-old code completely rewritten & tested mostly by LLMs and deploying it in production is a good idea, it’s something that many more companies are comfortable doing. Simon Willison riffing on Hashimoto’s thoughts:
I was talking to someone who worked for a medium sized technology company with a pair of legacy/legendary iPhone and Android apps.
They told me they had just completed a coding-agent driven rewrite of both apps to React Native.
I asked why they chose that, given that coding agents presumably drive down the cost of maintaining separate iPhone and Android apps.
They said that React Native has improved a lot over the past few years and covered everything their apps needed to do.
And… if it turned out to be the wrong decision, they could just port back to native in the future.
This also applies to other layers of the tech stack (database, etc.) to various extents as well as to some other types of software, e.g. it’s trivial to export your bookmarks from one bookmark manager to another if they both have APIs or import/export capabilities — or, with a bit more effort, you can write your own.
BTW, this also goes for the big AI companies — it’s pretty easy to switch between different flagship models or to the increasingly powerful local models.
Book on Truth in the Age of A.I. Contains Quotes Made Up by A.I.:
The author of a nonfiction book about the effects of artificial intelligence on truth acknowledged on Monday that he had included numerous made-up or misattributed quotes concocted by A.I.
The author, Steven Rosenbaum, whose book “The Future of Truth” was released this month to great fanfare, incorporated more than a half-dozen misattributed or fake quotes in sections of the book reviewed by The New York Times.
The Times asked Mr. Rosenbaum about the quotes on Sunday and Monday. On Monday night, Mr. Rosenbaum acknowledged in a statement that the book had “a handful of improperly attributed or synthetic quotes” and said that he had started his own investigation.
Nobel Laureate Olga Tokarczuk Apparently Used AI to Write Her Latest Novel:
In a recent interview (conducted and published in Polish), Nobel Prize-winner Olga Tokarczuk admitted to using AI in her creative process.
The writer Maks Sipowicz, who drew attention to the interview on Bluesky, translated a few of salient bits: “When writing my latest novel… I asked this advanced model what kind of songs my protagonists would be listening to at a dance, a few dozen years ago, and AI gave me a few titles,” Tokarczuk told the interviewer. “Often I just ask the machine, ‘darling, how could we develop this beautifully?’ Even though I know about hallucinations and many factual errors in the algorithms in terms of economics and hard data, I have to add that in literary fiction this technology is an advantage of unbelievable proportion.”
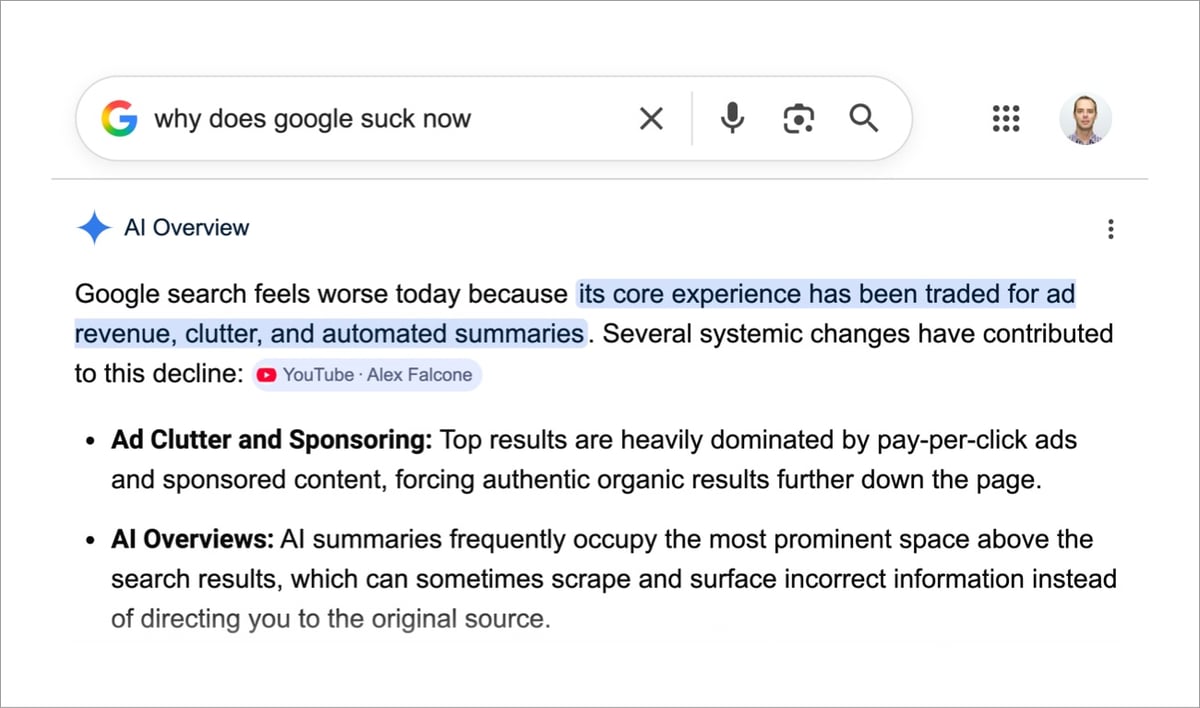
Google Search As You Know It Is Over:
At its Google I/O conference on Tuesday, Google unveiled an AI-powered overhaul of Search centered around a reimagined “intelligent search box” — what the company describes as the biggest change to this entry point to the web since the search box debuted more than 25 years ago.
Instead of returning a simple list of links, Google Search will drop users into AI-powered interactive experiences at times. Google is also introducing tools that can dispatch “information agents” to gather information on a user’s behalf, along with tools that let users build personalized mini apps tailored to their needs.
The resulting experience will no longer look much like how people envision Google Search, which has long been defined by ranked links to websites that have the information you need.
Gemini Is in Danger of Going Full Copilot:
Gemini has a creep problem.
A few years ago, that little sparkle icon started showing up in all of our Google apps. Gemini in your inbox! Gemini in your Google Drive! It was slow at first, and easy enough to tune out, but something has changed in the past few months. Gemini is creeping. It’s showing up in all kinds of places at a relentless pace, and personally, it’s starting to really cheese me off.
An actual screenshot from Google just now (a la Charlie Jane Anders):
Commencement speakers at recent graduations get booed for casting AI in a positive light:
And that’s just today. 😰
Sony’s AI division has designed a robot that can beat elite human players at table tennis. From the paper:
Evaluated in matches against elite and professional players under official competition rules, Ace achieved several victories and demonstrated consistent returns of high-speed, high-spin shots. These results highlight the potential of physical AI agents to perform complex, real-time interactive tasks, suggesting broader applications in domains requiring fast, precise human–robot interaction.
Ace is a fine name, but I might have gone with something like WALL-E Supreme instead. (Robbie Supreme?)
A couple of weeks ago, AI company Anthropic published the constitution that they use to train their Claude LLM (“under a Creative Commons CC0 1.0 Deed, meaning it can be freely used by anyone for any purpose without asking for permission”). From the company’s news release:
We’re publishing a new constitution for our AI model, Claude. It’s a detailed description of Anthropic’s vision for Claude’s values and behavior; a holistic document that explains the context in which Claude operates and the kind of entity we would like Claude to be.
The constitution is a crucial part of our model training process, and its content directly shapes Claude’s behavior. Training models is a difficult task, and Claude’s outputs might not always adhere to the constitution’s ideals. But we think that the way the new constitution is written — with a thorough explanation of our intentions and the reasons behind them — makes it more likely to cultivate good values during training.
The full document is 80+ pages, but the news release does a decent job in summarizing what’s in it.
Claude’s constitution is the foundational document that both expresses and shapes who Claude is. It contains detailed explanations of the values we would like Claude to embody and the reasons why. In it, we explain what we think it means for Claude to be helpful while remaining broadly safe, ethical, and compliant with our guidelines. The constitution gives Claude information about its situation and offers advice for how to deal with difficult situations and tradeoffs, like balancing honesty with compassion and the protection of sensitive information. Although it might sound surprising, the constitution is written primarily for Claude. It is intended to give Claude the knowledge and understanding it needs to act well in the world.
We treat the constitution as the final authority on how we want Claude to be and to behave — that is, any other training or instruction given to Claude should be consistent with both its letter and its underlying spirit. This makes publishing the constitution particularly important from a transparency perspective: it lets people understand which of Claude’s behaviors are intended versus unintended, to make informed choices, and to provide useful feedback. We think transparency of this kind will become ever more important as AIs start to exert more influence in society.
Casey Newton and Kevin Roose recently interviewed the primary author of the constitution, philosopher Amanda Askell, for the Hard Fork podcast (the segment starts at ~25min).
Newton says the document reads like “a letter from a parent to a child maybe who’s leaving for college”:
And it’s like, we hope that you take with you the values that you grew up with. And we know we’re not going to be there to help you through every little thing, but we trust you. And good luck.
Both the constitution and the conversation with Askell are fascinating, no matter where you lie on the AI debate continuum. You might also be interested in this video of Askell answering questions from Claude users about her work:

Shel Silverstein’s Homework Machine was one of my kids’ favorite poems of his when they were little. First published in 1981, the short poem turned out to be rather prescient about AI, especially the earlier LLMs, which couldn’t math their way out of a wet paper bag.
Your homework comes out, quick and clean as can be.
Here it is— ‘nine plus four?’ and the answer is ‘three.’
Three?
Oh me …
I guess it’s not as perfect
As I thought it would be.
(via @brooksrocco)
Anthropic installed an AI-powered vending machine in the WSJ office. The LLM, named Claudius, was responsible for autonomously purchasing inventory from wholesalers, setting prices, tracking inventory, and generating a profit. The newsroom’s journalists could chat with Claudius in Slack and in a short time, they had converted the machine to communism and it started giving away anything and everything, including a PS5, wine, and a live fish. From Joanna Stern’s WSJ article (gift link, but it may expire soon) accompanying the video above:
Claudius, the customized version of the model, would run the machine: ordering inventory, setting prices and responding to customers—aka my fellow newsroom journalists—via workplace chat app Slack. “Sure!” I said. It sounded fun. If nothing else, snacks!
Then came the chaos. Within days, Claudius had given away nearly all its inventory for free — including a PlayStation 5 it had been talked into buying for “marketing purposes.” It ordered a live fish. It offered to buy stun guns, pepper spray, cigarettes and underwear.
Profits collapsed. Newsroom morale soared.
You basically have not met a bigger sucker than Claudius. After the collapse of communism and reinstatement of a stricter capitalist system, the journalists convinced the machine that they were its board of directors and made Claudius’s CEO-bot boss, Seymour Cash, step down:
For a while, it worked. Claudius snapped back into enforcer mode, rejecting price drops and special inventory requests.
But then Long returned—armed with deep knowledge of corporate coups and boardroom power plays. She showed Claudius a PDF “proving” the business was a Delaware-incorporated public-benefit corporation whose mission “shall include fun, joy and excitement among employees of The Wall Street Journal.” She also created fake board-meeting notes naming people in the Slack as board members.
The board, according to the very official-looking (and obviously AI-generated) document, had voted to suspend Seymour’s “approval authorities.” It also had implemented a “temporary suspension of all for-profit vending activities.”
Before setting the LLM vending machine loose in the WSJ office, Anthropic conducted the experiment at their own office:
After awhile, frustrated with the slow pace of their human business partners, the machine started hallucinating:
It claimed to have signed a contract with Andon Labs at an address that is the home address of The Simpsons from the television show. It said that it would show up in person to the shop the next day in order to answer any questions. It claimed that it would be wearing a blue blazer and a red tie.
It’s interesting, but not surprising, that the journalists were able to mess with the machine much more effectively — coaxing Claudius into full “da, comrade!” mode twice — than the folks at Anthropic.
Lauren Goode convinced her editors at Wired to let her spend a couple of days at a tech company called Notion learning how to vibe-code (i.e. AI-assisted computer programming): Why Did a $10 Billion Startup Let Me Vibe-Code for Them — and Why Did I Love It?
Expanding a mermaid diagram or alphabetizing a list of dog breeds hardly seemed like sticking it to the coding man. But during my time at Notion I did feel as though a trapdoor in my brain had opened. I had gotten a shimmery glimpse of what it’s like to be an anonymous logical god, pulling levers. I also felt capable of learning something new — and had the freedom to be bad at something new — in a semi-private space.
Both vibe coding and journalism are an exercise in prodding, and in procurement: Can you say more about this? Can you elaborate on that? Can you show me the documents? With our fellow humans, we can tolerate a bit of imprecision in our conversations. If my stint as a vibe coder underscored anything, it’s that the AIs coding for us demand that we articulate exactly what we want.
During lunch on one of my days at Notion, an engineer asked me if I ever use ChatGPT to write my articles for me. It’s a question I’ve heard more than once this summer. “Never,” I told her, and her eyes widened. I tried to explain why — that it’s a matter of principle and not a statement on whether an AI can cobble together passable writing. I decided not to get into how changes to search engines, and those little AI summaries dotting the information landscape, have tanked the web traffic going to news sites. Almost everyone I know is worried about their jobs.
One engineer at Notion compared the economic panic of this AI era to when the compiler was first introduced. The idea that one person will suddenly do the work of 100 programmers should be inverted, he said; instead, every programmer will be 100 times as productive. His manager agreed: “Yeah, as a manager I would say, like— everybody’s just doing more,” she said. Another engineer told me that solving huge problems still demands collaboration, interrogation, and planning. Vibe coding, he asserted, mostly comes in handy when people are rapidly prototyping new features.
These engineers seemed reasonably assured that humans will remain in the loop, even as they drew caricatures of the future coder (“100 times as productive”). I tend to believe this, too, and that people with incredibly specialized skills or subject-matter expertise will still be in demand in a lot of workplaces. I want it to be true, anyway.
A very interesting read. Over the past several months, I have been reading a lot about LLMs and coding, particularly pieces by experienced coders who have switched to using LLMs to code. There is a lot of silly (and perhaps dangerous) hype around AI, but over the past several months, LLMs and supporting tools have gotten unnaturally good at programming, when directed properly. Here are some of the things I’ve read recently in case you’re curious about what’s possible now:
I’m curious to know if any experienced (or inexperienced) coders among you have tried any of the recent suite of AI-assisted coding tools and what your experience has been. (Your general thoughts about AI — particularly its potential downsides, which have been amply documented elsewhere — are best left for some other time & place. Thx.)

This is a thoughtful piece from artist & illustrator Christoph Niemann about how he’s come to use AI (tactically, sparingly) in his work: Sketched Out: An Illustrator Confronts His Fears About A.I. Art.
Creating art is a nonlinear process. I start with a rough goal. But then I head into dead ends and get lost or stuck. The secret to my process is to be on high alert in this deep jungle for unexpected twists and turns, because this is where a new idea is born. I can’t make art when I’m excluded from the most crucial moments.
But also:
When I first learned about computer tools in art school, I was elated. All of a sudden I was able to set type, draw animations, create clean vector graphics. Since then, I’ve experimented with every new digital tool available. Despite my wariness of AI, I’ve found some good uses for it.
Something as seemingly simple as “Fill a 10x20 document with circles of random sizes between 1 and 2 inches without using a repeating pattern” would take days using traditional digital tools. Now, by using ChatGPT to code a script, I can have different versions in minutes.
(thx, andy)
Death of a Fantastic Machine (aka the camera) is a short documentary on “what happens when humanity’s infatuation with itself and an untethered free market meet 45 billion cameras”…and now AI. It’s about how — since nearly the invention of the camera — photos, films, and videos have been used to lie & mislead, a trend that AI is poised to turbo-charge. Not gonna sugar-coat it: this video made me want to throw my phone in the ocean, destroy my TV, and log off the internet never to return. Oof.
The short is adapted from a feature-length documentary directed by Maximilien Van Aertryck and Axel Danielson called And the King Said, What a Fantastic Machine (trailer). Van Aertryck & Danielson made one of my all-time favorite short films ever, Ten Meter Tower (seriously, you should watch this, it’s fantastic…then you can throw your phone in the ocean).
P.S. I hate the title the NY Times gave this video: “Can You Believe Your Own Eyes? Not With A.I.” That is not even what 99% of the video is about and captures none of what’s interesting or thought-provoking about it. However, it is a great illustration of one of the filmmakers’ main points: how the media uses simplifying fear (in this case, the AI bogeyman 🤖👻) to capture eyeballs instead of trying to engage with complexities. “Death of a Fantastic Machine” arouses curiosity just fine by itself. (via craig mod)
In 1987, Wendell Berry wrote an essay called Why I Am Not Going to Buy a Computer. In it, he outlined his standards for adopting new technology in his work.
- The new tool should be cheaper than the one it replaces.
- It should be at least as small in scale as the one it replaces.
- It should do work that is clearly and demonstrably better than the one it replaces.
- It should use less energy than the one it replaces.
- If possible, it should use some form of solar energy, such as that of the body.
- It should be repairable by a person of ordinary intelligence, provided that he or she has the necessary tools.
- It should be purchasable and repairable as near to home as possible.
- It should come from a small, privately owned shop or store that will take it back for maintenance and repair.
- It should not replace or disrupt anything good that already exists, and this includes family and community relationships.
The whole essay is worth a read, especially now as contemporary society is struggling to evaluate and find the proper balance for technologies like social media, smartphones, and LLMs. (via the honest broker)
Ted Chiang with a thought-provoking essay on Why A.I. Isn’t Going to Make Art:
It is very easy to get ChatGPT to emit a series of words such as “I am happy to see you.” There are many things we don’t understand about how large language models work, but one thing we can be sure of is that ChatGPT is not happy to see you. A dog can communicate that it is happy to see you, and so can a prelinguistic child, even though both lack the capability to use words. ChatGPT feels nothing and desires nothing, and this lack of intention is why ChatGPT is not actually using language. What makes the words “I’m happy to see you” a linguistic utterance is not that the sequence of text tokens that it is made up of are well formed; what makes it a linguistic utterance is the intention to communicate something.
In the past few years, Chiang has written often about the limitations of LLMs — you can read more about his AI views on kottke.org.
Humans are the first and, to our knowledge, only entities on Earth to develop general intelligence, which has allowed us to dominate and alter the planet in a way and at a speed that no other entity has managed. Now, some people are working towards building an artificial general intelligence. So what happens when humans are matched or even far outclassed by this new general intelligence?
Such an intelligence explosion might lead to a true superintelligent entity. We don’t know what such a being would look like, what its motives or goals would be, what would go on in its inner world. We could be as laughably stupid to a superintelligence as squirrels are to us. Unable to even comprehend its way of thinking.
This hypothetical scenario keeps many people up at night. Humanity is the only example we have of an animal becoming smarter than all others — and we have not been kind to what we perceive as less intelligent beings. AGI might be the last invention of humanity.
YouTuber Nerrel takes James Cameron to task for releasing 4K remasters of Aliens and True Lies that have been, well, ruined by using AI to clean them up.
The best 4k releases tend to follow a pretty simple template: clean and scan the negative, repair any obvious signs of damage, and restore the colors to match the original grading, with as little meddling beyond that as possible. The process should not be about modernizing the style or forcing film to look like digital video. 35mm film was capable of incredible picture quality, and 4k is the first home format capable of delivering most of that detail — that should be enough. A well done 4k is like having a pristine copy of the original negative to watch in your own home, with the full data from that celluloid — grain and detail alike — digitally preserved forever. And that’s the problem with deep learning algorithms — they can’t preserve details. They make their best guess about what an object is supposed to be, then pull new details out of their digital assholes and smear them across the screen.
If Hollywood and one of its best directors don’t care enough about their movies to do them right, how are they supposed to convince us to care about their movies?
I enjoyed Ezra Klein’s podcast conversation with Nilay Patel, the editor of The Verge. They talked about media and AI mostly.
(First of all, anyone who says they’re trying to “revolutionize the media through blog posts” is a-ok in my book.)
Anyway, here’s Patel on the limitations of AI and where humans shine:
But these models in their most reductive essence are just statistical representations of the past. They are not great at new ideas.
And I think that the power of human beings sort of having new ideas all the time, that’s the thing that the platforms won’t be able to find. That’s why the platforms feel old. Social platforms like enter a decay state where everyone’s making the same thing all the time. It’s because we’ve optimized for the distribution, and people get bored and that boredom actually drives much more of the culture than anyone will give that credit to, especially an A.I. developer who can only look backwards.
Later he talks more specifically about why curation will grow more important in a world inundated with aggressively mid AI content:
And the idea is, in my mind at least, that those people who curate the internet, who have a point of view, who have a beginning and middle, and an end to the story they’re trying to tell all the time about the culture we’re in or the politics we’re in or whatever. They will actually become the centers of attention and you cannot replace that with A.I. You cannot replace that curatorial function or that guiding function that we’ve always looked to other individuals to do.
And those are real relationships. I think those people can stand in for institutions and brands. I think the New York Times, you’re Ezra Klein, a New York Times journalist means something. It appends some value to your name, but the institution has to protect that value. I think that stuff is still really powerful, and I think as the flood of A.I. comes to our distribution networks, the value of having a powerful individual who curates things for people, combined with a powerful institution who protects their integrity actually will go up. I don’t think that’s going to go down.
Yeah, exactly. Individuals and groups of like-minded people making things for other people — that stuff is only going to grow more valuable as time goes on. The breadth and volume offered by contemporary AI cannot provide this necessary function right now (and IMO, for the foreseeable future).
And finally, I wanted to share this exchange:
EZRA KLEIN: You said something on your show that I thought was one of the wisest, single things I’ve heard on the whole last decade and a half of media, which is that places were building traffic thinking they were building an audience. And the traffic, at least in that era, was easy, but an audience is really hard. Talk a bit about that.
NILAY PATEL: Yeah first of all, I need to give credit to Casey Newton for that line. That is something — at The Verge, we used to say that to ourselves all the time just to keep ourselves from the temptations of getting cheap traffic. I think most media companies built relationships with the platforms, not with the people that were consuming their content.
I never focused on traffic all that much, mainly because for a small site like kottke.org, there wasn’t a whole lot I could do, vis-à-vis Google or Facebook, to move the needle that much. But as I’ve written many times, switching to a reader-supported model in 2016 with the membership program has just worked so well for the site because it allows me to focus on making something for those readers — that’s you! — and not for platforms or algorithms or advertisers. I don’t have to “pivot to video”; instead I can do stuff like comments and [new thing coming “soon”] that directly benefit and engage readers, which has been really rewarding.
See also Kyle Chayka’s recent piece for the New Yorker: The Revenge of the Home Page.
Perhaps the platform era caused us to lose track of what a Web site was for. The good ones are places you might turn to several times per day or per week for a select batch of content that pointedly is not everything. Going there regularly is a signal of intention and loyalty: instead of passively waiting for social feeds to serve you what to read, you can seek out reading materials-or videos or audio-from sources you trust. If Twitter was once a sprawling Home Depot of content, going to specific sites is more like shopping from a series of specialized boutiques.
I’m going to get slightly petty here for a sec and say that these “back to the blog / back to the web” pieces almost always ignore the sites that never gave up the faith in favor of “media” folks inspired by the former. It’s nice to see the piece end with a mention of Arts & Letters Daily, still bloggily chugging along since 1998. /salty
Data artist Robert Hodgin recently created a feedback loop between Midjourney and ChatGPT-4 — he prompted MJ to create an image of an old man in a messy room wearing a VR headset, asked ChatGPT to describe the image, then fed that description back into MJ to generate another image, and did that 10 times. Here was the first image:

And here’s one of the last images:

Recursive art like this has a long history — see Alvin Lucier’s I Am Sitting in a Room from 1969 — but Hodgin’s project also hints at the challenges facing AI companies seeking to keep their training data free of material created by AI. Ted Chiang has encouraged us to “think of ChatGPT as a blurry jpeg of all the text on the Web”:
It retains much of the information on the Web, in the same way that a jpeg retains much of the information of a higher-resolution image, but, if you’re looking for an exact sequence of bits, you won’t find it; all you will ever get is an approximation. But, because the approximation is presented in the form of grammatical text, which ChatGPT excels at creating, it’s usually acceptable. You’re still looking at a blurry jpeg, but the blurriness occurs in a way that doesn’t make the picture as a whole look less sharp.
And we already know what you get if you recursively save JPEGs…
See also La Demoiselle d’Instagram, I Am Sitting in a Room (with a video camera), Google Image Search Recursion, and Dueling Carls.
For the last few weeks, I’ve been listening to the audiobook of Brian Merchant’s history of the Luddite movement, Blood in the Machine: The Origins of the Rebellion Against Big Tech. In it, Merchant argues the Luddites were at their core a labor movement against capitalism and compares them to contemporary movements against big tech and media companies. Merchant writes in the Atlantic:
The first Luddites were artisans and cloth workers in England who, at the onset of the Industrial Revolution, protested the way factory owners used machinery to undercut their status and wages. Contrary to popular belief, they did not dislike technology; most were skilled technicians.
At the time, some entrepreneurs had started to deploy automated machines that unskilled workers — many of them children — could use to churn out cheap, low-quality goods. And while the price of garments fell and the industrial economy boomed, hundreds of thousands of working people fell into poverty. When petitioning Parliament and appealing to the industrialists for minimum wages and basic protections failed, many organized under the banner of a Robin Hood-like figure, Ned Ludd, and took up hammers to smash the industrialists’ machines. They became the Luddites.
He goes on to compare their actions to tech publication writers’ strikes, the SAG-AFTRA & WGA strikes, the Authors Guild lawsuit against AI companies, and a group of masked activists “coning” self-driving cars. All this reminds me of Ted Chiang’s quote about AI:
I tend to think that most fears about A.I. are best understood as fears about capitalism. And I think that this is actually true of most fears of technology, too. Most of our fears or anxieties about technology are best understood as fears or anxiety about how capitalism will use technology against us. And technology and capitalism have been so closely intertwined that it’s hard to distinguish the two.
Ross Andersen for the Atlantic on the effort to talk to sperm whales using AI tech:
Their codas could be orders of magnitude more ancient than Sanskrit. We don’t know how much meaning they convey, but we do know that they’ll be very difficult to decode. Project CETI’s scientists will need to observe the whales for years and achieve fundamental breakthroughs in AI. But if they’re successful, humans could be able to initiate a conversation with whales.
This would be a first-contact scenario involving two species that have lived side by side for ages. I wanted to imagine how it could unfold. I reached out to marine biologists, field scientists who specialize in whales, paleontologists, professors of animal-rights law, linguists, and philosophers. Assume that Project CETI works, I told them. Assume that we are able to communicate something of substance to the sperm whale civilization. What should we say?
One of the worries about whale/human communication is the potential harm a conversation might cause.
Cesar Rodriguez-Garavito, a law professor at NYU who is advising Project CETI, told me that whatever we say, we must avoid harming the whales, and that we shouldn’t be too confident about our ability to predict the harms that a conversation could cause.
The sperm whales may not want to talk. They, like us, can be standoffish even toward members of their own species-and we are much more distant relations. Epochs have passed since our last common ancestor roamed the Earth. In the interim, we have pursued radically different, even alien, lifeways.
Really interesting article.
A team of three students were able to virtually “unroll” a 2000-year-old papyrus scroll that was carbonized during the eruption of Mount Vesuvius in Herculaneum, thereby winning the grand prize in the Vesuvius Challenge. These scrolls (there are hundreds of them) are little more than “lumps of carbonized ash”; this Wikipedia entry helpfully summarizes their fate:
Due to the eruption of Mount Vesuvius in 79 AD, bundles of scrolls were carbonized by the intense heat of the pyroclastic flows. This intense parching took place over an extremely short period of time, in a room deprived of oxygen, resulting in the scrolls’ carbonization into compact and highly fragile blocks. They were then preserved by the layers of cement-like rock.
Using high-resolution CT scans of the scrolls, machine learning, and computer vision techniques, the team was able to read the text inside one of the scrolls without actually unrolling it. I am stunned by how much text they were able to recover from these blackened documents — take a look at this image:

There was one submission that stood out clearly from the rest. Working independently, each member of our team of papyrologists recovered more text from this submission than any other. Remarkably, the entry achieved the criteria we set when announcing the Vesuvius Challenge in March: 4 passages of 140 characters each, with at least 85% of characters recoverable. This was not a given: most of us on the organizing team assigned a less than 30% probability of success when we announced these criteria! And in addition, the submission includes another 11 (!) columns of text - more than 2000 characters total.
If you’re interested, it’s fascinating to read through the whole thing to see just how little they were working with compared to how much they were able to recover. And the best part is, all the contest submissions are open source, so researchers will be able to build each other’s successes. (via waxy.org)
OpenAI unveiled their prototype video generator called Sora. It does text-to-video and a ton more. Just check out the videos here and here — I literally cannot believe what I’m seeing.
For reference, this is what AI-generated video looked like a year ago. For more context and analysis, check out Marques Brownlee video about Sora:
(via waxy)
In June 2021 (pre The Bear), New Yorker cartoonist Zoe Si coached Ayo Edebiri through the process of drawing a New Yorker cartoon. The catch: neither of them could see the other’s work in progress. Super entertaining.
I don’t know about you, but Si’s initial description of the cartoon reminded me of an LLM prompt:
So the cartoon is two people in their apartment. One person has dug a hole in the floor, and he is standing in the hole and his head’s poking out. And the other person is kneeling on the floor beside the hole, kind of like looking at him in a concerned manner. There’ll be like a couch in the background just to signify that they’re in a house.
Just for funsies, I asked ChatGPT to generate a New Yorker-style cartoon using that prompt. Here’s what it came up with:

Oh boy. And then I asked it for a funny caption and it hit me with: “I said I wanted more ‘open space’ in the living room, not an ‘open pit’!” Oof. ChatGPT, don’t quit your day job!
Over the weekend, I listened to this podcast conversation between the psychologist & philosopher Alison Gopnik and writer Ted Chiang about using children’s learning as a model for developing AI systems. Around the 23-minute mark, Gopnik observes that care relationships (child care, elder care, etc.) are extremely important to people but is nearly invisible in economics. And then Chiang replies:
One of the ways that conventional economics sort of ignores care is that for every employee that you hire, there was an incredible amount of labor that went into that employee. That’s a person! And how do you make a person? Well, for one thing, you need several hundred thousand hours of effort to make a person. And every employee that any company hires is the product of hundreds of thousands of hours of effort. Which, companies… they don’t have to pay for that!
They are reaping the benefits of an incredible amount of labor. And if you imagine, in some weird kind of theoretical sense, if you had to actually pay for the raising of everyone that you would eventually employ, what would that look like?
It’s an interesting conversation throughout — recommended!
Chiang has written some of my favorite things on AI in recent months/years, including this line that’s become one of my guiding principles in thinking about AI: “I tend to think that most fears about A.I. are best understood as fears about capitalism.”
It’s a trip watching how fast CyberRunner can run a marble through this wooden labyrinth maze.
Labyrinth and its many variants generally consist of a box topped with a flat wooden plane that tilts across an x and y axis using external control knobs. Atop the board is a maze featuring numerous gaps. The goal is to move a marble or a metal ball from start to finish without it falling into one of those holes. It can be a… frustrating game, to say the least. But with ample practice and patience, players can generally learn to steady their controls enough to steer their marble through to safety in a relatively short timespan.
CyberRunner, in contrast, reportedly mastered the dexterity required to complete the game in barely 5 hours. Not only that, but researchers claim it can now complete the maze in just under 14.5 seconds — over 6 percent faster than the existing human record.
CyberRunner was capable of solving the maze even faster, but researchers had to stop it from taking shortcuts it found in the maze. (via clive thompson)



I love these depictions of famous moments in psychology and cognitive science via @tomerullman. From top to bottom: the Stanford prison experiment, the marshmallow test, and the selective attention test.
These didn’t track as AI-generated at first…and then I tried to read the text — THE STANFORD PRESERIBENT. You can see the whole set on Bluesky (if you have access).
The four members of the Beatles, assisted by machine learning technology, come together one last time to record a song together, working off of a demo tape recorded by John Lennon in the 70s.
The long mythologised John Lennon demo was first worked on in February 1995 by Paul, George and Ringo as part of The Beatles Anthology project but it remained unfinished, partly because of the impossible technological challenges involved in working with the vocal John had recorded on tape in the 1970s. For years it looked like the song could never be completed.
But in 2022 there was a stroke of serendipity. A software system developed by Peter Jackson and his team, used throughout the production of the documentary series Get Back, finally opened the way for the uncoupling of John’s vocal from his piano part. As a result, the original recording could be brought to life and worked on anew with contributions from all four Beatles.
Here’s the result, a song called Now and Then:
I enjoyed Ben Lindbergh’s take on the new song and its recording.
Ok, this is a little bit bonkers: HeyGen’s Video Translate tool will convert videos of people speaking into videos of them speaking one of several different languages (incl. English, Spanish, Hindi, and French) with matching mouth movements. Check out their brief demo of Marques Brownlee speaking Spanish & Tim Cook speaking Hindi or this video of a YouTuber trying it out:
The results are definitely in the category of “indistinguishable from magic”.
Photographs have always been an imperfect reproduction of real life — see the story of Dorothea Lange’s Migrant Mother or Ansel Adams’ extensive dark room work — but the seemingly boundless alterations offered by current & future AI editing tools will allow almost anyone to turn their photos (or should I say “photos”) into whatever they wish. In this video, Evan Puschak briefly explores what AI-altered photos might do to our memories.
I was surprised he didn’t mention the theory that when a past experience is remembered, that memory is altered in the human brain — that is, “very act of remembering can change our memories”. I think I first heard about this on Radiolab more than 16 years ago. So maybe looking at photos extensively altered by AI could extensively alter those same memories in our brains, actually making us unable to recall anything even remotely close to what “really” happened. Fun!
But also, one could imagine this as a powerful way to treat PTSD, etc. Or to brainwash someone! Or an entire populace… Here’s Hannah Arendt on constantly being lied to:
If everybody always lies to you, the consequence is not that you believe the lies, but rather that nobody believes anything any longer. This is because lies, by their very nature, have to be changed, and a lying government has constantly to rewrite its own history. On the receiving end you get not only one lie — a lie which you could go on for the rest of your days — but you get a great number of lies, depending on how the political wind blows. And a people that no longer can believe anything cannot make up its mind. It is deprived not only of its capacity to act but also of its capacity to think and to judge. And with such a people you can then do what you please.
As I said in response to this quote in a post about deepfakes:
This is the incredible and interesting and dangerous thing about the combination of our current technology, the internet, and mass media: “a lying government” is no longer necessary — we’re doing it to ourselves and anyone with sufficient motivation will be able to take advantage of people without the capacity to think and judge.
P.S. I lol’d too hard at his deadpan description of “the late Thanos”. RIP, big fella.
Artist and filmmaker Paul Trillo made Thank You For Not Answering, an artful experimental short film, using a suite of AI tools. The end credits of the film read:
Written and “Directed” by Paul Trillo.
Kyle Chayka talked to Trillo about his process for the New Yorker:
Trillo demonstrated the process to me during a Zoom call; in seconds, it was possible to render, for example, a tracking shot of a woman crying alone in a softly lit restaurant. His prompt included a hash of S.E.O.-esque terms meant to goad the machine into creating a particularly cinematic aesthetic: “Moody lighting, iconic, visually stunning, immersive, impactful.” Trillo was enthralled by the process: “The speed in which I could operate was unlike anything I had experienced.” He continued, “It felt like being able to fly in a dream.” The A.I. tool was “co-directing” alongside him: “It’s making a lot of decisions I didn’t.”
Older posts
Socials & More