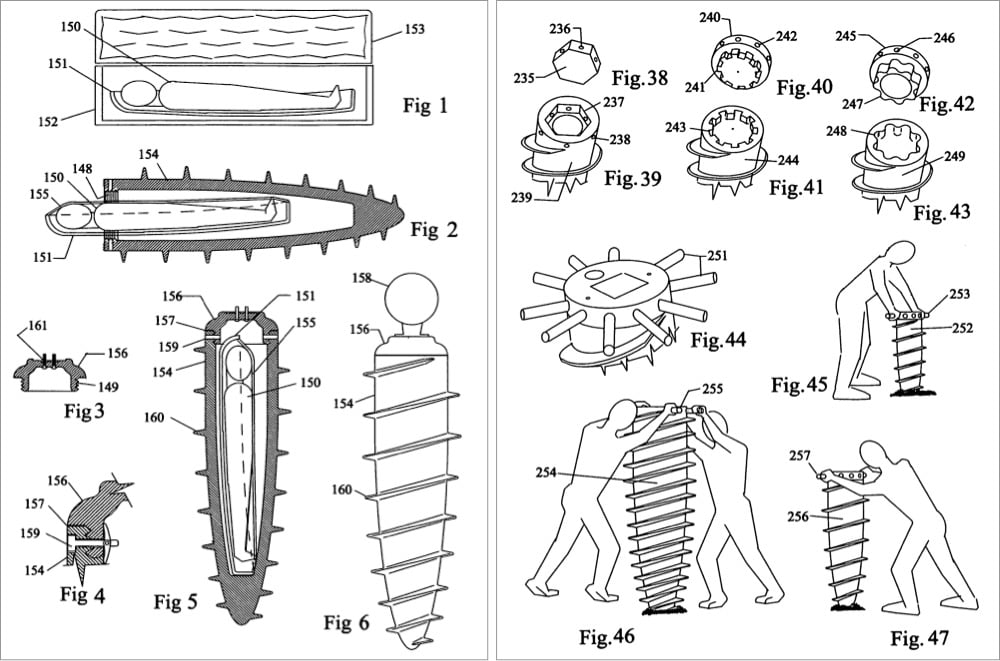
I was with some friends having a couple of drinks and one of them mentioned he had to go talk to some people about an automatic grave digger, which meant a huge amount of dirt removal. And I said, “Why don’t we just make a big large carrot shaped thing with threads around it and screw it into the ground?”
Scruggs says that burying someone in his coffin is “no more trouble than putting a fencepost in”.
Popular Mechanics has a quick look at 15 Patents That Changed the World, including the maglev train from back in 1967, the 3d printer, a “bionic eye” retinal prosthesis from 1968, GPS, CRISPR-Cas9, and graphene. Fun to read through but I’m including it here because it was found through Chris Anderson who had this comment:
One thing that allowed the modern drone industry to innovate so fast is that most of the core patents were filed by aerospace companies back in the mid-twentieth century and have since expired. The quadcopter patent, for example, was filed in 1962 https://t.co/rY0zLzqAAE
Earlier today I tweeted this Boing Boing post about the upcoming US public domain infusion, the first since 1998. In the case of both patents and copyright, it’s important to remember the innovation and creativity their release provides, not just the original work or invention it represents.
Yesterday, there was a wall of Tesla patents in the lobby of our Palo Alto headquarters. That is no longer the case. They have been removed, in the spirit of the open source movement, for the advancement of electric vehicle technology.
Tesla Motors was created to accelerate the advent of sustainable transport. If we clear a path to the creation of compelling electric vehicles, but then lay intellectual property landmines behind us to inhibit others, we are acting in a manner contrary to that goal. Tesla will not initiate patent lawsuits against anyone who, in good faith, wants to use our technology.
Damn good move for a damn good reason. It’s impressive to watch this company in action.
Update: I read that last line quoted above again and perhaps “abandoned” is too strong a word. Glenn Fleishman notes on Twitter:
They did not abandon their patents. They aren’t apparently even licensing them. They are stating they won’t sue except defensively. The devil is in the details. Twitter released a complete framework of their policy when they announced the same thing.
Hopefully Musk and co. will clarify what they mean by “in good faith”.
The IPA is a new way to do patent assignment that keeps control in the hands of engineers and designers. It is a commitment from Twitter to our employees that patents can only be used for defensive purposes. We will not use the patents from employees’ inventions in offensive litigation without their permission. What’s more, this control flows with the patents, so if we sold them to others, they could only use them as the inventor intended.
This is a significant departure from the current state of affairs in the industry. Typically, engineers and designers sign an agreement with their company that irrevocably gives that company any patents filed related to the employee’s work. The company then has control over the patents and can use them however they want, which may include selling them to others who can also use them however they want. With the IPA, employees can be assured that their patents will be used only as a shield rather than as a weapon.
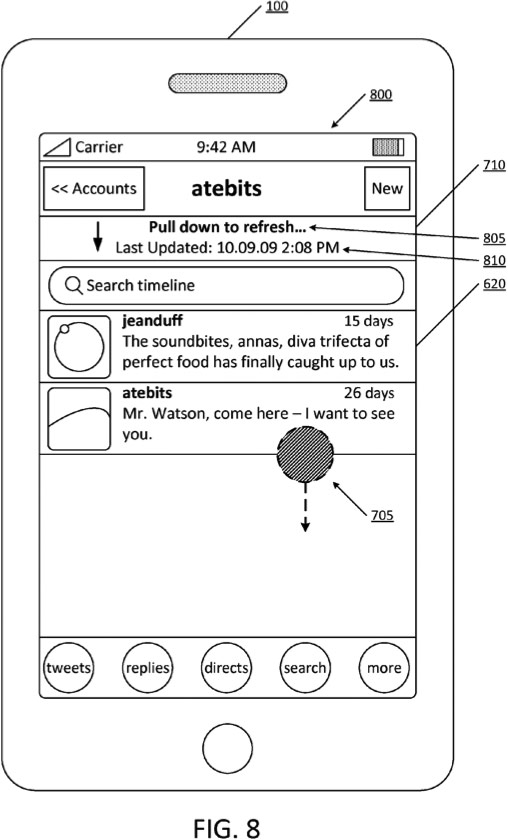
Loren Brichter invented the “pull to refresh” interface mechanism for Tweetie, a Twitter app he eventually sold to Twitter. Apparently he patented the idea sometime before the sale, so Twitter now owns the patent.
Update: A reader pointed out that this is not a patent…it’s a patent application that hasn’t even been reviewed yet. But it’s clearly a novel invention and most likely will be accepted when reviewed. (thx, mike)
Finally got around to listening to the excellent episode of This American Life on patents: When Patents Attack! The episode surveys the state of the US patent system, using Nathan Myhrvold’s smarmy Intellectual Ventures as a hook to tell the story.
In polls, as many as 80 percent of software engineers say the patent system actually hinders innovation. In other words, it does exactly the opposite of what it’s supposed to do. It doesn’t encourage them to come up with new ideas and create new products, it actually gets in their way.
The Economist chimed in as well, saying that the American patent system is “a travesty which threatens the wealth and welfare of the whole world”.
At a time when our future affluence depends so heavily on innovation, we have drifted toward a patent regime that not only fails to fulfil its justifying function, to incentivise innovation, but actively impedes innovation.
Devices using the system would send networks a description of their requirements — for example, a phone call or access to the internet — and receive back bids with a per-minute cost, or flat rate, at which those needs could be met. Users can either manually accept the bid that looks best to them, or have the phone choose one automatically, based on pre-programmed criteria.
Besides being a brain-dead obvious idea — nice work once again, USPTO — if a system like this were put in place, calling Mom on Mother’s Day would get a whole lot more expensive, as would calls and data usage during other peak times or locations.
Update: I’m reminded that this is just an application, not an accepted patent, so my “nice work” comment doesn’t apply. But I would imagine that patents coming from Google have little trouble getting accepted. (thx, mike)
On May 22, 1886, The Washington Post published a shocking front-page scoop: Zenas F. Wilber, a former Washington patent examiner, swore in an affidavit that he’d been bribed by an attorney for Alexander Graham Bell to award Bell the patent for the telephone over a rival inventor, Elisha Gray, who’d filed a patent document on the same day as Bell in 1876.
Even though Bell has been legally vindicated on this issue, Seth Shulman’s new book, The Telephone Gambit, suggests that he did in fact steal a key idea from Elisha Gray. (via house next door)
In its Office Action released 9 October 2007, the Patent Office found that the prior art I found and submitted completely anticipated the broadest claims of the patent, U.S. Patent No. 5,960,411.
The patent is not off the books yet…Amazon has a chance to respond before that happens. People have been waiting for this for a long time. (via marginal revolution)
A 1993 New Yorker story by John Seabook called The Flash of Genius is being made into a movie starring Greg Kinnear. The story revolves around Bob Kearns, the inventor of the intermittent windshield wiper and his struggle to get the US auto industry to pay him for infringing on his patent. “There’s no question that Dr. Kearns’ wiper circuit was interesting. He had a three-brush motor, with dynamic brake and intermittent on one speed only — his system was a concatenation of a lot of different ideas. But we figured there was just no way in the world it was patentable. An electronic timing device was an obvious thing to try next. How can you patent something that is in the natural evolution of technology?”
BTW, the phrase “flash of genius” refers to a test of patentability enacted in 1941 saying that the act of invention had to be a “flash of creative genius” on the part of the inventor and not the result of tinkering. That standard was replaced in 1952 by the non-obviousness test.
Chris Anderson talked about, ba ba baba!, not the long tail. Well, not explicitly. Chris charted how the availability of a surplus in transistors (processors are cheap), storage (hard drives are cheap), and surplus in bandwidth (DSL is cheap) has resulted in so much opportunity for innovation and new technology. His thoughts reminded me of how surplus space in Silicon Valley (in the form of garages) allowed startup entrepreneurs to pursue new ideas without having to procure expensive commercial office space.
Roger Brent crammed a 60 minute talk into 20 minutes. It was about genetic engineering and completely baffling…almost a series of non sequiturs. “Centripital glue engine” was my favorite phrase of the talk, but I’ve got no idea what Brent meant by it.
Homaro Cantu gave a puzzling presentation of a typical meal at his Chicago restaurant, Moto. I’ve seen this presentation twice before and eaten at Moto; all three experiences were clear and focused on the food. This time around, Cantu didn’t explain the food as well or why some of the inventions were so cool. His polymer box that cooks on the table is a genuinely fantastic idea, but I got the feeling that the rest of the audience didn’t understand what it was. Cantu also reiterated his position on copyrighting and patenting his food and inventions. Meg caught him saying that he was trying to solve the famine problem with his edible paper, which statement revealed two problems: a) famines are generally caused by political issues and therefore not solvable by new kinds of food, printed or otherwise, and b) he could do more good if he open sourced his inventions and let anyone produce food or improve the techniques in those famine cases where food would be useful.
Richard Dawkins gave part of his PopTech talk (the “queerer than we can suppose” part of it) at TED in 2005 (video).
Bob Metcalfe’s wrap-up of the conference was a lot less contentious than in past years; hardly any shouting and only one person stormed angrily out of the room. In reference to Hasan Elahi’s situation, Bob said that there’s a tension present in our privacy desires: “I want my privacy, but I need you to be transparent.” Not a bad way of putting it.
Serena Koenig spoke about her work in Haiti with Partners in Health. Koening spoke of a guideline that PIH follows in providing healthcare: act as though each patient is a member of your own family. That sentiment was echoed by Zinhle Thabethe, who talked about her experience as an HIV+ woman living in South Africa, an area with substandard HIV/AIDS-related healthcare. Thabethe’s powerful message: we need to treat everyone with HIV/AIDS the same, with great care. Sounds like the beginning of a new Golden Rule of Healthcare.
Andreas Pavel was the inventor of the portable music player (aka Walkman). “I was in the woods in St. Moritz, in the mountains. The snow was falling down. I pressed the button, and suddenly we were floating. It was an incredible feeling, to realize that I now had the means to multiply the aesthetic potential of any situation.”
Surowiecki on the sorry state of the US patent system. “Since the [USPTO] is funded by patent fees, as opposed to getting its budget from Washington, it has a financial incentive to process applications as quickly, rather than as diligently, as possible.”
Twenty percent of the human genome is patented. I expect that someday in the future, my morning will be interrupted by a lawyer telling me that the company he represents holds a patent on the biochemical conversion of foodstuffs to energy suitable for powering a biological organism and that I should cease and desist eating my Cheerios.
Ok, bad first question since it seems unlikely that Nelson and Google would write up this application just to have a few laughs. So here’s a better question: where’s the prior art on this? The patent was filed on 12/31/2003. I floated the idea of embedding advertising into RSS ads in October 2002 and there was prior art then. But Google’s patent application covers “targeted ads” in a “syndicated, e.g., RSS, presentation format in an automated manner”. Curiously, I believe this is already covered by an older Google patent, filed in 12/2002:
The relevance of advertisements to a user’s interests is improved. In one implementation, the content of a web page is analyzed to determine a list of one or more topics associated with that web page. An advertisement is considered to be relevant to that web page if it is associated with keywords belonging to the list of one or more topics. One or more of these relevant advertisements may be provided for rendering in conjunction with the web page or related web pages.
That’s Google AdSense in a nutshell: inserting targeted ads into web documents in an automated manner. So what is it about RSS/Atom files that make them different than plain old web pages and hence not covered under the 2002 AdSense patent? Nothing. This vocabulary of “feeds” and “syndication” is still misleading. RSS/Atom files, especially as they are described in the 12/2003 patent application, are XML files that sit on a web server waiting for someone with a web browser to come along to read them, just like XHTML files:
So, people access documents written in a markup language that have been published on a Web server with a software application. If this seems familiar to you, it should. It’s called Web browsing and has nothing to do with syndication. RSS readers and newsreaders are just specialized Web browsers…
The 12/2003 application tries to explain the difference between HTML pages and “syndicated content formats” thusly:
Syndicated content, unlike web pages which are normally stored in an HTML format, are often stored and presented in what may be described as a syndicated content format. Syndicated content formats are often XML (eXtended Markup Language) based and include structured representations of content such as news articles, search results, and web log entries. Syndicated content formats are primarily intended for providing syndicated information, e.g., news headlines, weblogs, etc. in a structured format such as a list of items, with another device, e.g., a user device, usually controlling the ultimate presentation format of the items in the list. This is in contrast to HTML which usually includes a fair amount of presentation and formatting information within an HTML document such as a web page.
That’s a pretty weak explanation and sounds a lot like what a web browser (the “user device” that controls the presentation) does with XHTML files (XML-based files without a “fair amount of presentation and formatting information”). It sounds to me like Google already has this covered with their previous patent.
[Long aside: Does the prior art of embedding AdSense ads in XHTML files invalidate this patent? Patents are tricky because they don’t cover ideas, they cover specific implementations of ideas. While the 12/2003 application states that “said syndicated format is an XML compliant format” it also specifies that “said syndicated format is a format for listing items corresponding to a channel, said received information including a listing of at least two items and including for each item, a title and a link”. That is, the XML files they’re talking about have to be RSS/Atom-ish in nature. This doesn’t rule out XHTML files in theory, but it does rule out many of them in practice.
But the really tricky part with these software patents is that the implementations of ideas are written so broadly that they might as well be patents of the ideas themselves. If you look at it that way (the patent-holding companies certainly seem willing to litigate on that basis), Google has already embedded automated, targeted advertising into XML-based files. According to news.com, Google launched their AdSense service in June 2003. When the first AdSense advertisement was embedded in an XHTML file soon after that, well, there’s your prior art on the very thing that Google attempted to patent 6 months later.]
Now Google, whose name has become synonymous with internet searching, plans to build a database that will compare the track record and credibility of all news sources around the world, and adjust the ranking of any search results accordingly.
The database will be built by continually monitoring the number of stories from all news sources, along with average story length, number with bylines, and number of the bureaux cited, along with how long they have been in business. Google’s database will also keep track of the number of staff a news source employs, the volume of internet traffic to its website and the number of countries accessing the site.
Google will take all these parameters, weight them according to formulae it is constructing, and distil them down to create a single value. This number will then be used to rank the results of any news search.
This overall score, or METASCORE, is a weighted average of the individual critic scores. Why a weighted average? When selecting our source publications, we noticed that some critics consistently write better (more detailed, more insightful, more articulate) reviews than others. In addition, some critics and/or publications typically have more prestige and weight in the industry than others. To reflect these factors, we have assigned weights to each publication (and, in the case of film, to individual critics as well), thus making some publications count more in the METASCORE calculations than others.
I wonder if these systems will eventually let their users tweak the credibility algorithms to their liking. For instance, it won’t take long for conservatives to start complaining about the liberal bias of Google News. In the case of Metacritic, I’d like them to ignore Anthony Lane’s rating when he writes about summer blockbusters and put greater emphasis on whatever Ebert has to say. In the meantime, I’m readying my patent applications for RecipeRank, PhotoRank, ModernFurnitureRank, SoftDrinkRank, and, oooh, PatentRank. I’m sure they’re brilliantly unique enough to be recognized by the US Patent Office as new inventions.
Stay Connected