Growing Up Heroes
The Growing Up Heroes blog is collecting photos of little kids wearing superhero costumes. (thx, jasons)
Update: See also I Used To Be Younger.
This site is made possible by member support. ❤️
Big thanks to Arcustech for hosting the site and offering amazing tech support.
When you buy through links on kottke.org, I may earn an affiliate commission. Thanks for supporting the site!
kottke.org. home of fine hypertext products since 1998.
The Growing Up Heroes blog is collecting photos of little kids wearing superhero costumes. (thx, jasons)
Update: See also I Used To Be Younger.
Classic Geocities site: Walter Miller’s Home page. Suck featured the site back in Jan 1996 when it was on Prodigy. According to Ready Steadman Go, Suck co-founder Carl Steadman was rumored to be behind Miller’s site. Ready Steadman Go was run by Ben and Mena Trott, who also formed a little company called Six Apart which makes the software on which kottke.org runs.
Anyway, Walter’s Home page will soon be gone. Looks like Cartoon Girls I Wanna Nail has already been banished to the land of wind and ghosts. Oh, and whatever happened to Carl? Plastic is still going but is he still at the helm? (via waxy)
Update: Geocities is now dead, and Walter Miller’s Home page with it. Here’s an archived version. (thx, tim)
The Vintage Web blog consists of screenshots of sites whose current design appears to have not been updated since the 1990s.
Farhad Manjoo on the unrecognizable Internet of 1996.
I started thinking about the Web of yesteryear after I got an e-mail from an idly curious Slate colleague: What did people do online back when Slate launched, he wondered? After plunging into the Internet Archive and talking to several people who were watching the Web closely back then, I’ve got an answer: not very much.
David Wertheimer calls bullshit and retorts:
The World Wide Web was an invigorating, compelling and, frankly, amazing place in 1996. Innovations were fast, furious and quickly adopted. Clever people did clever things and pretty much everyone noticed, because “everyone” was a rather small and curious community. […] The Internet of 1996 was certainly nothing like today’s experience. But to suggest there wasn’t much to do is to ignore everything that was being done.
I’m obviously with Team David on this one.
I Love You Forever and Always is a collection of scanned love letters and other notes written to a boy called Jon by various girls in the mid-1980s. If you grew up in the 80s, Jon’s collection is instant crack-like nostalgia.
Greg Allen still has his bottle of Suck Cola from when the now-defunct web site Suck was handing them out at a trade show in 1996. He’s building a registry of Suck Cola bottles…if you’ve got one, send in the details.
After your Cola information is reviewed and validated, you will be issued a Suck Cola Registry Number. I have designated my bottle SC0005, having reserved the first four Registry Numbers, SC0001-SC0004, for Suck.com co-founders Joey Anuff and Carl Steadman.
Suck the web site has now been dead for as long as it was active, but the Cola lives on.
Dan’s 20th Century Abandonware page showcases one man’s collection of “legacy software, computer systems and memorabilia”. I’ve got a CD of FutureSplash (an early version of Flash) somewhere. And a NeXT pencil! (via mark)
Andy Baio has digitized and put online a VHS tape from 1995 called “Internet Power!” Gape in wonder at its mid-90s-ness.
Speaking of mining the archives of kottke.org, I just found this post that quotes a message board post by Ben Affleck about why he posts his thoughts to the web:
I think there is some responsibility on the part of those folks who benefit from the attentions of some section of the public to be responsive to that group.
It’s worth noting that Affleck was one of the first celebrities to post online in a bloggish manner…he’d answer people’s questions on his site’s message board. (His site is now dead, but a couple of instances of the board were collected by archive.org.)
I remember one post of his in particular (which I can’t find on archive.org). Ben was up late, at like 3am, playing Everquest (or maybe Ultima Online?) because he was addicted and couldn’t stop. He also mentioned that he was essentially playing the game instead of being in bed with his girlfriend at the time, Gwyneth Paltrow.
Last week, Rex Sorgatz reviewed the 15-year-old first issue of Wired; lo and behold, Wired founding editor Louis Rossetto sent him a lengthy response that’s a whole lot more interesting than the original review (sorry, Rex).
This beta was a full-on 120 page prototype, with actual stories re-purposed from other places, actual art, actual ads (someone quipped that it was the ultimate editor’s wet dream to be able to pick their own ads), and then all the sections and pacing that was to go into the actual magazine. The cover was lifted from McLuhan’s The Medium is the Massage; it was the startling black and white image of a guy’s head with a big ear where his eyes should have been. The whole thing got printed and laminated in a copy shop in Berkeley that had just got a new Kodak color copier and rip. Jane, Eugene, and I went in when the shop closed on Friday evening and worked round the clock through the weekend. Took 45 minutes to print out one color page! We emerged Monday morning with the prototype, which we had spiral-bound in a shop in South San Francisco, before we boarded a plane for Amsterdam to present it to Origin’s founder and CEO Eckart Wintzen, to see if he would approve the concept, agree to advertise in the magazine, and then give us the advance we crucially needed to keep the project alive.
Regarding my earlier post on how Heather Champ’s jezebel.com came to be in Gakwer’s hands, she sold it to them directly: “When the good folks at Gawker contacted me a couple of months ago, I realized that she would find a good home amongst their properties.” (thx, meg)
Jezebel is a new Gawker Media blog about…well, that’s not important. Anyway, the site is hosted at jezebel.com, which was the former personal domain of Heather Champ and the original home of The Mirror Project (timeline). Heather put the domain up for sale in January 2004…I guess Nick bought it?
Update: Never fear, vintage Jezebel merchandise is still available.
Regarding the Twitter vs. Blogger thing from earlier in the week, I took another stab at the faulty Twitter data. Using some educated guesses and fitting some curves, I’m 80-90% sure that this is what the Twitter message growth looks like:
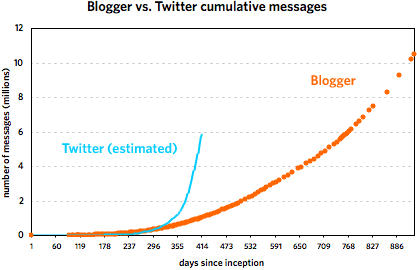
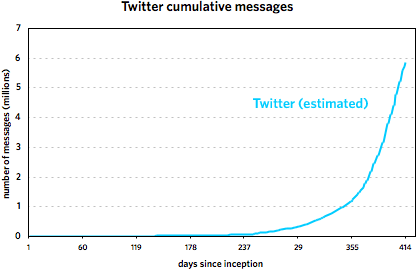
These graphs cover the following time periods: 8/23/1999 - 3/7/2002 for Blogger and 3/21/2006 - 5/7/2007 for Twitter. It’s important to note that the Twitter trend is not comprised of actual data points but is rather a best-guess line, an estimate based on the data. Take it as fact at your own risk. (More specifically, I’m more sure of the general shape of the curve than with the steepness. My gut tells me that the curve is probably a little flatter than depicted rather than steeper.)
That said, most of what I wrote in the original post still holds, as do the comments in subsequent thread. Twitter did not grow as fast as the faulty data indicated, but it did get to ~6,000,000 messages in about half the time of Blogger. Here are the reasons I offered for the difference in growth:
1. Twitter is easier to use than Blogger was and had a lower barrier to entry.
2. Twitter has more ways to update (web, phone, IM, Twitterific) than did Blogger.
3. Blogger’s growth was limited by a lack of funding.
4. Twitter had a larger pool of potential users to draw on.
5. Twitter has a built-in social aspect that Blogger did not.
And commenters in the thread noted that:
6. Twitter’s 140-character limit encourages more messages.
7. More people are using Twitter for conversations than was the case with Blogger.
What’s interesting is that these seeming advantages (in terms of message growth potential) for Twitter didn’t result in higher message growth than Blogger over the first 9-10 months. But then the social and network effects (#5 and #7 above) kicked in and Twitter took off.
Archive of the first commercial web site, GNN, launched in August 1993. More on GNN.
Important update: I’ve re-evaluated the Twitter data and came up with what I think is a much more accurate representation of what’s going on.
Further update: The Twitter data is bad, bad, bad, rendering Andy’s post and most of this here post useless. Both jumps in Twitter activity in Nov 2006 and March 2007 are artificial in nature. See here for an update.
Update: A commenter noted that sometime in mid-March, Twitter stopped using sequential IDs. So that big upswing that the below graphs currently show is partially artificial. I’m attempting to correct now. This is the danger of doing this type of analysis with “data” instead of data.
—
In mid-March, Andy Baio noted that Twitter uses publicly available sequential message IDs and employed Twitter co-founder Evan Williams’ messages to graph the growth of the service over the first year of its existence. Williams co-founded Blogger back in 1999, a service that, as it happens, also exposed its sequential post IDs to the public. Itching to compare the growth of the two services from their inception, I emailed Matt Webb about a script he’d written a few years ago that tracked the daily growth of Blogger. His stats didn’t go back far enough so I borrowed Andy’s idea and used Williams’ own blog to get his Blogger post IDs and corresponding dates. Here are the resulting graphs of that data.1
The first one covers the first 253 days of each service. The second graph shows the Twitter data through May 7, 2007 and the Blogger data through March 7, 2002. [Some notes about the data are contained in this footnote.]
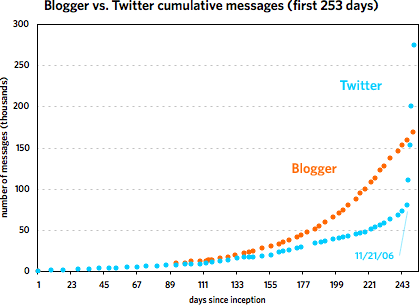
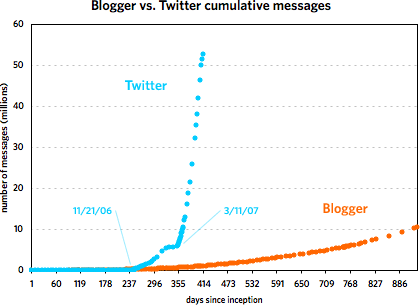
As you can see, the two services grew at a similar pace until around 240 days in, with Blogger posts increasing faster than Twitter messages. Then around November 21, 2006, Twitter took off and never looked back. At last count, Twitter has amassed five times the number of messages than Blogger did in just under half the time period. But Blogger was not the slouch that the graph makes it out to be. Plotting the service by itself reveals a healthy growth curve:
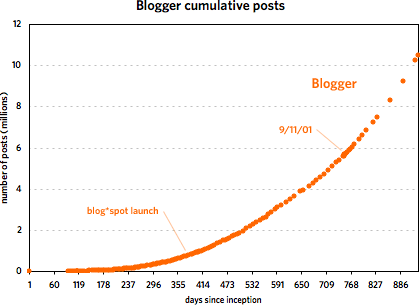
From late 2001 to early 2002, Blogger doubled the number of messages in its database from 5M to 10M in under 200 days. Of course, it took Twitter just over 40 days to do the same and under 20 days to double again to 20M. The curious thing about Blogger’s message growth is that large events like 9/11, SXSW 2000 & 2001, new versions of Blogger, and the launch of blog*spot didn’t affect the growth at all. I expected to see a huge message spike on 9/11/01 but there was barely a blip.
The second graph also shows that Twitter’s post-SXSW 2007 growth is real and not just a temporary bump…a bunch of people came to check it out, stayed on, and everyone messaged like crazy. However, it does look like growth is slowing just a bit if you look at the data on a logarithmic scale:
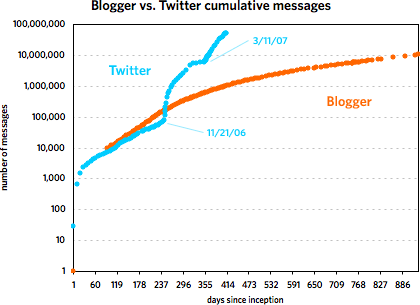
Actually, as the graph shows, the biggest rate of growth for Twitter didn’t occur following SXSW 2007 but after November 21.
As for why Twitter took off so much faster than Blogger, I came up with five possible reasons (there are likely more):
1. Twitter is easier to use than Blogger was. All you need is a web browser or mobile phone. Before blog*spot came along in August 2000, you needed web space with FTP access to set up a Blogger blog, not something that everyone had.
2. Twitter has more ways to create a new message than Blogger did at that point. With Blogger, you needed to use the form on the web site to create a post. To post to Twitter, you can use the web, your phone, an IM client, Twitterrific, etc. It’s also far easier to send data to Twitter programatically…the NY Times account alone sends a couple dozen new messages into the Twitter database every day without anyone having to sit there and type them in.
3. Blogger was more strapped for cash and resources than Twitter is. The company that built Blogger ran out of money in early 2001 and nearly out of employees shortly after that. Hard to say how Blogger might have grown if the dot com crash and other factors hadn’t led to the severe limitation of its resources for several key months.
4. Twitter has a much larger pool of available users than Blogger did. Blogger launched in August 1999 and Twitter almost 7 years later in March 2006. In the intervening time, hundreds of millions of people, the media, and technology & media companies have become familiar and comfortable with services like YouTube, Friendster, MySpace, Typepad, Blogger, Facebook, and GMail. Hundreds of millions more now have internet access and mobile phones. The potential user base for the two probably differed by an order of magnitude or two, if not more.
5. But the biggest factor is that the social aspect of Twitter is built in and that’s where the super-fast growth comes from. With Blogger, reading, writing, and creating social ties were decoupled from each other but they’re all integrated into Twitter. Essentially, the top graph shows the difference between a site with social networking and one largely without. Those steep parts of the Twitter trend on Nov 21 and mid-March? That’s crazy insane viral growth2, very contagious, users attracting more users, messages resulting in more messages, multiplying rapidly. With the way Blogger worked, it just didn’t have the capability for that kind of growth.
A few miscellaneous thoughts:
It’s important to keep in mind that these graphs depict the growth in messages, not users or web traffic. It would be great to have user growth data, but that’s not publicly available in either case (I don’t think). It’s tempting to look at the growth and think of it in terms of new users because the two are obviously related. More users = more messages. But that’s not a static relationship…perhaps Twitter’s userbase is not increasing all that much and the message growth is due to the existing users increasing their messaging output. So, grain of salt and all that.
What impact does Twitter’s API have on its message growth? As I said above, the NY Times is pumping dozens of messages into Twitter daily and hundreds of other sites do the same. This is where it would be nice to have data for the number of active users and/or readers. The usual caveats apply, but if you look at the Alexa trends for Twitter, pageviews and traffic seem to leveling out. Compete, which only offers data as recently as March 2007, still shows traffic growing quickly for Twitter.
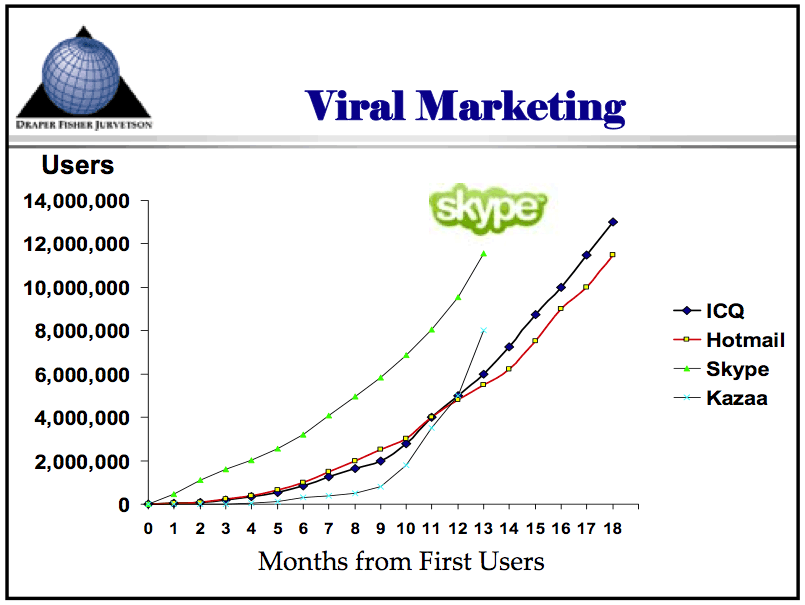
Just for comparison, here’s a graph showing the adoption of various technologies ranging from the automobile to the internet. Here’s another graph showing the adoption of four internet-based applications: Skype, Hotmail, ICQ, and Kazaa (source: a Tim Draper presentation from April 2006).
[Thanks to Andy, Matt, Anil, Meg, and Jonah for their data and thoughts.]
[1] Some notes and caveats about the data. The Blogger post IDs were taken from archived versions of Evhead and Anil Dash’s site stored at the Internet Archive and from a short-lived early collaborative blog called Mezzazine. For posts prior to the introduction of the permalink in March 2000, most pages output by Blogger didn’t publish the post IDs. Luckily, both Ev and Anil republished their old archives with permalinks at a later time, which allowed me to record the IDs.
The earliest Blogger post ID I could find was 9871 on November 23, 1999. Posts from before that date had higher post IDs because they were re-imported into the database at a later time so an accurate trend from before 11/23/99 is impossible. According to an archived version of the Blogger site, Blogger was released to the public on August 23, 1999, so for the purposes of the graph, I assumed that post #1 happened on that day. (As you can see, Anil was one of the first 2-3 users of Blogger who didn’t work at Pyra. That’s some old school flavor right there.)
Regarding the re-importing of the early posts, that happened right around mid-December 1999…the post ID numbers jumped from ~13,000 to ~25,000 in one day. In addition to the early posts, I imagine some other posts were imported from various Pyra weblogs that weren’t published with Blogger at the time. I adjusted the numbers subsequent to this discontinuity and the resulting numbers are not precise but are within 100-200 of the actual values, an error of less than 1% at that point and becoming significantly smaller as the number of posts grows large. The last usable Blogger post ID is from March 7, 2002. After that, the database numbering scheme changed and I was unable to correct for it. A few months later, Blogger switched to a post numbering system that wasn’t strictly sequential.
The data for Twitter from March 21, 2006 to March 15, 2007 is from Andy Baio. Twitter data subsequent to 3/15/07 was collected by me. ↩
[2] “Crazy insane viral growth” is a very technical epidemiological term. I don’t expect you to understand its precise meaning. ↩
The Game Neverending Museum contains several screenshots and a paper transformation matrix. I got a little nostalgic for Web 1.0 looking at this.
1994 best/worst-of the internet lists with predicitons for 1995. “Pick any tragic event and you can probably recall seeing a newsgroup that taunted its seriousness. There was alt.tonya-harding.whack.whack.whack. Then we had alt.lorena.bobitt.chop.chop.chop. And no, I haven’t forgotten alt.oj-simpson.drive.faster.”
50 greatest commercials of the 1980s. Amazingly includes video of every single commercial…prepare to waste your entire afternoon. (thx, art)
Update: Here are dozens of additional 80s commercials. (thx, david)
Matt Haughey’s got a few photos of Flickr HQ from back when they had only 4 or 5 employees and were still in Vancouver. Includes a screenshot of Flickr at the time, when it was still “all chat and shoeboxes”.
Blast from the past: MRWong’s Soup’Partments, the world’s tallest virtual building.
Today is the WWW’s 15th birthday. “Links to the fledgling computer code for the www were put on the alt.hypertext discussion group so others could download it and play with it. On that day the web went world wide.” Here’s the alt.hypertext posting where Tim Berners-Lee releases the WWW to the world.
Gopher, developed in 1991 at the University of Minnesota, is a text-only, hierarchical document search and retrieval protocol that was supplanted by the more flexible WWW in the mid-1990s. Some servers running this old protocol are still alive, however. The WELL, an online discussion board and community that started back in 1985, is still running a Gopher server. If you’ve got a recent version of Firefox, you can check it out in its original Gopher-y state at gopher://gopher.well.com/ or with any web browser at http://gopher.well.com:70/.
It seems to have been frozen in early 1996 or so and houses several historical documents from the early 1990s. Many of the links are dead and some documents cannot be found, but poking around for 20 minutes or so, I found:
One of the articles by Sterling, his remarks from a privacy conference in 1994, touches on a topic that’s still hotly debated today:
I’ve been asked to explain why I don’t worry much about the topics of privacy threat raised by this panel. And I don’t. One reason is that these scenarios seem to assume that there will be large, monolithic bureaucracies (of whatever character, political or economic) that are capable of harnessing computers for one-way surveillance of an unsuspecting populace. I’ve come to feel that computation just doesn’t work that way. Being afraid of monolithic organizations especially when they have computers, is like being afraid of really big gorillas especially when they are on fire.
I don’t follow Sterling’s writing that closely, but I wonder if he’s changed his mind on this issue?
Matisse Enzer helped set up The WELL’s Gopher server and tells how it came to be on his blog. And here are a few other Gopher servers that are still running:
gopher://aerv.nl/1
gopher://hal3000.cx/1
gopher://quux.org/1
gopher://sdf.lonestar.org/11/users
http://gopherproject.org/Software/Gopher
Update: It occurs to me that this might be up the alley of Digg’s users. If you’ve got an account there, you may wish to Digg this story.
Update: Here’s a write-up of GopherCon ‘92, “a small working session of Gopher developers and users”. I liked this bit:
Ed Vielmetti of CICnet gave a talk on “what we would be gathering to discuss if UMinn had never developed Gopher”, meaning primarily World-Wide Web (WWW). WWW was developed for the high-energy physics community and serves as a model of what Gopher could do if a discipline-oriented virtual community invested in it heavily.
Thanks for sending that along, Ed.
Update: The archives of the infamous spies.com Gopher server appear to be here. I don’t know how complete they are or when they’re from. (via digg)
Phil Gyford has posted a demo version of HotWired’s web site from 1995. See also Jeff Veen’s look back at some of HotWired’s designs.
Update: Net Surf covers The Spot and Yahoo getting VC and moving off of Stanford’s servers. And the background on this story by Josh Quittner, oy vey!
Dave Jamieson used to collect baseball cards and recently uncovered his stash when he cleaned out the closet of his childhood home. In attempting to recoup some of the time and money spent in his youth on this cardboard, Jamieson found that baseball cards aren’t as popular or as lucrative as they used to be:
Baseball cards peaked in popularity in the early 1990s. They’ve taken a long slide into irrelevance ever since, last year logging less than a quarter of the sales they did in 1991. Baseball card shops, once roughly 10,000 strong in the United States, have dwindled to about 1,700. A lot of dealers who didn’t get out of the game took a beating. “They all put product in their basement and thought it was gonna turn into gold,” Alan Rosen, the dealer with the self-bestowed moniker “Mr. Mint,” told me. Rosen says one dealer he knows recently struggled to unload a cache of 7,000 Mike Mussina rookie cards. He asked for 25 cents apiece.
Close readers of kottke.org know that I collected sports cards too. I got involved in this prepubescent hobby later than most; I was 14 or 15 when a friend and his older brother — who was around 24 and collecting for investment — introduced me to it. And I loved it:
I still have them all somewhere, in boxes, collecting dust faster than value. The Ken Griffey Jr. Upper Deck rookie, the 130 different Nolan Ryan cards, the complete 1989 Hoops set (with the David Robinson rookie), and several others I really can’t remember right now.
I used to spend untold hours sifting through them, looking up the values in Beckett’s Price Guide, visiting card shops, flipping through commons to complete sets, looking for patterns in Topps’ rack packs (I scored many a Jim Abbott rookie with this technique), chewing that ancient bubble gum (I bought a pack of 1983 cards once and chewed the gum…it was horrible), and keeping track of the total value of my collection with a Lotus 1-2-3 spreadsheet on my dad’s 286. It was a lot of fun at the time (as the Web is fun for me now); I guess that’s about all one can ask for from a hobby.
Recently I stumbled across The Baseball Card Blog and was hit by a giant wave of nostalgia for my old obsession. One thing led to another — you know how that goes — and before I knew it, a package was speeding its way to me from a card shop in Pennsylvania containing several 1989 Fleer & Donruss wax packs, a 1989 Topps rack pack, and a couple of 1987 Topps wax packs.1
I’ve been opening a pack every few days since they arrived. Smell is the sense most powerfully associated with memory, so getting a whiff of that cardboard is really sending me back. Like a wine connoisseur, I can even smell the difference between each brand of card; the smell of Topps cards holds the strongest memories for me…the 1989 Topps set was my favorite. I opened the ‘87 Topps packs with a fellow ex-collector, but when we tried to chew the gum, it tasted like the cards and turned to a muddy dust in our mouths. But that was mostly what happened even when the gum was new, so we were unsurprised.
Because of the aforementioned slump in the baseball card collecting economy, the card packs I ordered were the same price I paid for them as a kid (factoring for inflation), even though they’re almost 20 years old and way more scarce. Back then, I used most of my $5/week allowance on cards, and it took weeks and months of patience to buy enough packs to complete a set, procure that Griffey rookie card, or amass enough Mark McGwires to trade to a friend for a desired Nolan Ryan.
As an adult, I have the cashflow to buy any card I want whenever I want (within reason). Or several boxes of cards, so as to compile complete sets instantly. Or I can just purchase the complete sets and skip the intermediate step. I could buy an entire box of 1989 Upper Deck packs — at $1.25 per pack and nearly impossible to find in rural Wisconsin, an unimaginable extravagance for me as a kid — right now on eBay. When I think about the financial advantages I now have over my 16-yo self in collecting the same exact cards, I feel like the NY Yankees (and their monster payroll) competing in a Single A league. It’s unfair and even thinking about collecting cards in that manner takes a lot of the fun out of it for me. If I do start collecting cards again, I’m going to approach it like I did back then: by hand, a little at a time, and treating even the essentially worthless commons with care. Unless Nolan Ryan is involved…in that case, the sky’s the limit, although I might have to sell my bicycle to get it. In the meantime, I’m waiting for the next household footwear purchase so I can put my newly purchased cards in the shoe box for safe keeping.
[1] A quick note on terminology. A “wax pack” is a basic pack of around 15 cards (plus gum, when cards still had gum packaged with them), so-called because the packages used to be sealed with wax. (Now they’re all probably packaged in plastic and whatnot…I don’t know, I haven’t kept up.) The bottom card in such a pack is called a “wax back” because the card got a thin layer of wax on it from the sealing process. A “rack pack” is a hanging triple pack made of see-thru plastic. A “common” is an ordinary card not worth very much, as opposed to cards or rookies, hot prospects, all-stars, and the like. A “box” contains several wax packs, typically 20-40 packs/box. A “complete set” is a collection of every card sold by a company in a particular year. The ‘89 Topps set had 792 cards. Sets were sold in factory-sealed boxes or were compiled by hand from cards acquired in packs. ↩
Back in 9/2000, over a hundred bloggers recorded their day in photos and text…alas, most of those galleries are gone; only the listings remain. It’s funny, bloggers are their own paparazzi and archivists, but they’re not doing a very good job of it; there’s little material publicly available from those early days.
Jeff Veen is posting some old screencaps of hotwired.com on Flickr; this one’s from 1994. Early 1995. Late 1995. 1996. 1997 (Packet!). 1998. 1999. 2006.
Update: Jeff has some further thoughts on the Hotwired design.
A CBC report from 1993 on a global phenomenon called “Internet”. (thx, joshua)
Update: Here’s a mirror on YouTube.
Interview with Amy Franceschini, founder of Futurefarmers. Franceschini also had a hand in Atlas Magazine (blast from the past!), which was one of my favorite sites back in the day.
After four days as a porn site, suck.com is back to its old self. No explanation yet about the outage.
{kind=link}
{kind=link}
Stay Connected