Weblogs and power laws
Many systems and phenomena are distributed according to a power law distribution. A power law applies to a system when large is rare and small is common. The distribution of individual wealth is a good example of this: there are a very few rich men and lots & lots of poor folks. A familiar way to think about power laws is the 80/20 rule: 80% of the wealth is controlled by 20% of the population.
It’s been shown that the distribution of links on the web scales according to a power law, so it comes as no surprise that the distribution of links to weblogs does as well. Taking the top 100 most linked to weblogs on Technorati as a data set (specifically from 1/24/03), I used Excel to plot and fit a curve to the data:
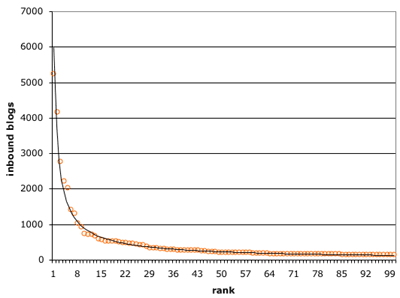
The data conforms quite well to a power law curve. The R-squared value, a measure of how well the curve fits the data (1.0 is a perfect fit), is 0.9918. I ran a similar analysis of the distribution of the top 200 inbound referers to kottke.org and observed a fit of the data to a power law curve (R-squared = ~0.95). Clay Shirky showed that the distribution of the number of outbound links in the LiveJournal community follows a power law. Paul Hammond has observed a similar pattern with his outgoing links.**
This NEC study reveals that the deviation of a set of data from the power law correlates to how much competition is present in the system. The better the fit, the more competitive the environment is. Again, no surprise that the system of weblogs is a highly competitive one.
But what are weblogs competing for? Matt Webb posits that power laws arise due to scarcity. Links themselves can’t be scarce (a page can have as many links as it can hold without running out), but they are a measure of something that is: people.
More specifically, the time that people have for visiting sites and linking to sites is limited. Mary only has so much time for visiting weblogs; if she goes to BoingBoing, she doesn’t have time for MetaFilter. Some visitors are linkers and they link what they visit. Similarly, linkers have only so much time for linking. Sam can link to 20 sites about airplanes, but he can’t link to 5000. The scarcity of people’s time results in the distribution of links that can be described using power laws.
** Other places you *might* find power laws in the weblog world if you took the time to look: Daypop Top 40, Blogdex top links, the Blogging Ecosystem (in both “most linked” and “most prolific linkers” data sets), average # of posts per weblog, average # of words per post, average # of smileys per post, # of visitors per weblog, # of comments per post per weblog, and so on…
Further reading on weblogs, power laws, small worlds, the 80/20 rule, the rich get richer phenomena, Zipf’s Law, Pareto’s Law, etc.:
Small worlds & LiveJournal (Matt Webb)
Like bloggers link like bloggers (Steve Himmer)
The weblog them, the weblog us (Tom Coates)
Internet Navigators Think Small (MSNBC)
Scarcity and power laws (Matt Webb)
Ecosystems, Power Laws, Counters (N.Z. Bear)
Power Laws, Weblogs, and Inequality (Clay Shirky)
Small Worlds (Duncan Watts)
Linked: The New Science of Networks (Albert-László Barabási)
Nexus: Small Worlds and the Groundbreaking Science of Networks (Mark Buchanan)
Ubiquity: The Science of History, or Why the World Is Simpler Than We Think (Mark Buchanan)
Six Degrees: The Science of a Connected Age
Reader comments
jkottkeFeb 09, 2003 at 6:39PM
Addendum: I wrote this post last week (Wednesday or Thursday, can't remember exactly), but didn't publish it until today. Clay Shirky published an article called Power Laws, Weblogs, and Inequality on similar issues over the weekend (probably prompted by these two threads, same as me). Rather than modify my post to include a discussion of Clay's findings, I decided to leave it the way it was. I added a link to his article under "further reading" and figure that the discussion here will apply to both. Have at it!
jkottkeFeb 09, 2003 at 7:19PM
Dave weighs in on Clay's article on Scripting News. A snippet:
"The scaling equation for weblogs is, emphatically, not like BBSes, mail lists, not like the Well. The popularity of this weblog does nothing to interfere with the growth of lawblogs, or warblogs, or bizblogs, medblogs, governmentblogs, divinityblogs, you name it. Perhaps within each there may be some hierarchy because humans build hierarchies like other primates. No big news there."
An important thing to remember here is that the web (and weblogs) is a scale-free network, meaning that the power law works at whatever scale you wish to apply it. Within the bizblogs vertical, the power law still holds...there are a few weblogs that get most the links and the traffic. According to Clay, how powerful those few bizblogs are depends on how many blogs are in that vertical.
Here's an example: the distribution of fame follows a power law. Michael Jackson is somewhere near the top of the heap, while 5.99 billion of the rest of us are somewhere in that right part of the curve. It's very hard for someone to get where Michael Jackson is in terms of fame.
But you can measure fame within smaller groups of people as well. Tim Berners-Lee is pretty famous among web programming types...most of the rest of the web programming people are not. It's very hard for someone to get to where Tim Berners-Lee is in terms of fame among web programming people.
The thing you can't get away from is that when there are 2,000 weblogs, getting into the top 10% most-linked is hard, but when there are 2,000,000 weblogs, getting into the top 10% most-linked is very, very hard. And when everyone on earth has a weblog, getting into the top 10% most linked will be very, very, very, very hard.
Scripting News may not take any links away from other weblogs (that's the wrong way to think about it anyway), but if Dave continues to update the site in a consistant manner, it will grow faster relative to most of the lower-ranked weblogs. Think of it as "rising tides lift all boats" but instead of the water being horizontally flat, it's shaped like a power law curve and rises according to the power law equation (i.e. the left side rises faster than the right).
Adam GreenfieldFeb 09, 2003 at 8:18PM
I won't quibble with the general fitness of the power-law curve to the blogosphere, since the numbers are there to be seen.
But something that occurs to me is that blogs are not fungible in quite the same way as other types of sites. If the core of our definition of "blog" is a site driven by one, or at most a few, distinct voices, then it's easier to break into the upper stratum than the numbers would imply.
Although there is a limited amount of time any individual can devote to reading other blogs daily, we don't seem to have "Mark slots" or "Heather slots" or "Jason slots" per se. There's generally room for one more voice.
Which suggests to me that if you can come up with something new to say (admittedly difficult) or a new way of saying it meaningfully (curiously and gratifyingly, somewhat easier), there's room at the "top" for you.
And anyway, none of us is getting any younger.
Eric ScheidFeb 09, 2003 at 10:40PM
I've also noticed the power law in effect in the inter-page links which occur on a wiki, which is interesting because links are typically made based on the merits of the information, and not due to either a cult of personality or simply high visibility.
mathowieFeb 09, 2003 at 10:46PM
That's interesting Eric. I wonder stats from a very large, dispersed wiki (like wikipedia) would follow the same curve. If so, that'd be really interesting, since it would seem with the content at wikipedia, it should be equally important stuff (if you assume the authors on all subjects were a similar level of experts).
Eric ScheidFeb 09, 2003 at 10:56PM
I'm starting to think that the observable power-law distributions are not due to politics, personality, or influence at all, but are due instead to benefits afforded by such networks.
A key article prompting this thought is at Nature: Language evolved in a leap, where they describe some mathematical models of word usage.
One implication of this is that just maybe we should stop taking this all so personally -- the fact that blogs conform to a power-law distribution is a good thing, for the community, and everyone benefits.
Rahul DaveFeb 09, 2003 at 11:29PM
I'm a bit confused. The top 100 blogs on technorati do not form a community in any way..they do give a power law, but this is a conclusion with very little predictive power since there is no need for there to be a special correlation between, for example, the topics in blog A in tier 3 and blog B in tier 3. The audiences may be entirely different for these two blogs, in other words, its not clear if there are sufficient statistics for a statement about the 'horizon of interest' for both communities.
I wonder how the choice of incoming blogs rather than incoming links from blogs may change things.
In general though, if one takes into account clustering, and chooses samples clustered according to topic one might find hierarchical rather than power law distribs(see barabasi's latest work on arxiv, or at the link http://tig.nareau.com/2003/01/03.html#a345). But even more generally, the existence of aggregators, trackback and comments are changing the unidirectionality of the web to a weighted directionality, and I suspect, this will weaken the power law conclusions over time. These are in the language of competition entities that have automatic mechanisms that help us cope with the scarcity of time, especially if we can unify and aggregate them.
matt pfefferFeb 10, 2003 at 2:18AM
I don't think Matt Webb's script measures scarcity. It will produce the same result for any finite value (of the resource), and finite isn't a useful definition for scarce at all -- for practical purposes, any arbitrarily large (but finite) amount of a resources is just as good as an infinite amount (I mean, there is, for example, some finite amount of money that is still more than you could ever spend in your lifetime, making it a virtually unlimited resource). I don't know perl, but I'd guess he wrote the script so that each subsequent chunk taken from the resource is some proportion of what had remained -- which would mean each subsequent percentage is of a smaller whole, so naturally it scales toward the lower percentages. But that doesn't say anything about whether the initial amount was "scarce", only that it was finite.
Carl BeethFeb 10, 2003 at 6:37AM
That weblog popularity adhere to a power law distribution is not surprising. What would be much more interesting to look into is the ways it tends to breaks it for other media.
At the end of the day when I look at what I have read during the day the variety of sources never ceases to amaze me. Readers of traditional media be it online of offline don't get this breadth. The typical webloger is more loyal to an idea than a source so he tends to link whoever expresses it the best.
There are other interesting things to look into: Comments and trackback like features have a tendency to flatten the power curve if you count voices instead of pure weblog popularity.
blakeFeb 10, 2003 at 9:25AM
From: “Tyranny of the Moment” Thomas Hylland Eriksen
In information society, the scarcest resource for people on the supply side of the economy is neither iron ore nor sacks of grain, but the attention of others. Everyone who works in the information field – from weather forecasters to professors – compete over the same seconds, minutes and hours of other people’s lives. Unlike what happens to physical objects, the amount of information does not diminish when one gives it away or sells it.
matt webbFeb 10, 2003 at 10:57AM
I don't think Matt Webb's script measures scarcity. It will produce the same result for any finite value (of the resource), and finite isn't a useful definition for scarce at all
The sad truth is I'm a bad man and my internal definition of "scarce" would probably get me beaten to death with sticks by economists.
I'm using scarce to mean 'something that can be used only once'. So, the number of hits on a website isn't scarce (to a certain limit), because one hit by person A doesn't preclude another hit by person B. But apples (say) *are* scarce: if I eat an apple, you can't eat that same one.
So that's what surprised me. By choosing random chunks from a scarce quantity (one unit can only be allocated to a single chunk), as opposed to just choosing random numbers, I got a power law instead of a Normal distribution.
And yes it ~naturally~ scales like that, but I like to check things. That's all the script it for.
So how does this apply to weblogs? Well it's tenuous and difficult without a model of how readers operate. But to have a guess:
Each reader has X amount of time. When they encounter a weblog, they spend a random amount of the time they have left reading it. Then they move to the next weblog. Rank the weblogs they read in order of time spent on them... a power law.
So add in another assumption: the chance of a given person encountering a weblog is some function of how much reading time other people spend on it (writing, reading, etc).
Would the combination of these two assumptions produce a weblog model with a power law distribution? I don't know. I should probably check. But it's fun guessing.
(And if anyone knows the technical definition of 'scarce', please let me know before I make an even bigger fool of myself.)
mathowieFeb 10, 2003 at 11:09AM
There are other interesting things to look into: Comments and trackback like features have a tendency to flatten the power curve if you count voices instead of pure weblog popularity.
I don't think they would flatten the curve much, really. Not to go all power-law-curve again, but if you plotted total comments per blog among technorati's output (or avg. comments per post), I believe you'd get the same curve, but with different names in different places. At the top (and probably responsible for most of all total weblog comments), you'd see slashdot, fark, kuro5hin, and metafilter, then more group weblogs, then individual weblogs with large comment followings.
Since many blogs have no comments, they would actually reach zero and become the tail end of the curve. So while Instapundit would be zero, since he has no comments, a blog like 9622 might be pretty high up in the ranking, though I doubt the curve would flatten much.
AnneFeb 10, 2003 at 12:38PM
"An important thing to remember here is that the web (and weblogs) is a scale-free network..."
I'm sorry, but I'm confused ;)
Where are the people in these discussions? What, exactly, constitute scale-free social interactions?
What does this tell us about computing and social lives? About collective action? What does this tell us about how people negotiate meaning or what they value in their interaction with others?
How does this help us build devices and applications that help people?
Or maybe I'm just completely missing the point ;)
matt pfefferFeb 10, 2003 at 12:40PM
Each reader has X amount of time. When they encounter a weblog, they spend a random amount of the time they have left reading it. Then they move to the next weblog.
But that's actually a pretty strong assumption, isn't it? Do people really spend less time reading a weblog, so they can get to another one before their spare time runs out? I would have thought people probably read weblogs for their own enjoyment, and therefore don't feel they need to get to them all in a certain amount of time; they just go to the next one when they think they'll enjoy it more than the one they're reading now.
And I definitely disagree with the second part of the above assumption. People don't spend a random amount of time on a given weblog; assuming they're rational, the time they spend on it will be related to how much they like it.
I guess I think human preferences (what we tend to like) are critical in determining how these things scale. People often share certain tastes (and lots of people also have some desire to fit in -- that is, develop the same tastes as other people). It's precisely because a person's level of interest in a weblog isn't random that we get these power laws, I think.
(Aside to Matt Webb -- Not trying to give a hard time here, at all; it's interesting to me, too. Good stuff.)
Dave S.Feb 10, 2003 at 12:48PM
Interesting analysis. The thing the struck me the most however was that out of the top 5 linked sites on the list, 3 were official sites for blogging tools. Considering the default installations of each link back to their respective sites (assuming Userland does this, since I've never used it) this shouldn't be a surprise.
The other two being common, mainstream, non-blog sites (cnn and google), if you remove the top five, the curve starts looking a lot more linear.
kennyFeb 10, 2003 at 4:31PM
physicsweb had an article a while back on the physics of the web :) and it's interesting how power law behaviour falls out of the attention economy. as an aside btw, it's also interesting how power law behaviour is influencing a fundamental rethink of boltzmann-gibbs entropy :)
filchyboyFeb 10, 2003 at 4:44PM
This topic is fascinating but one assumption seems to be that "linking" is the only currency of blogs. That strikes me as wrong. Certainly it is facile currency easily analyzed through a power law mapping. But the only currency? I think not.
David PostFeb 10, 2003 at 6:13PM
Fascinating thread. Two points about power law phenomena that have not been mentioned here. One is that the most common explanation for power laws in the natural world is 'preferential attachment' [or 'the rich get richer']. You can generate power law distributions where in circumstances where the probability that, say, a randomly selected web page will link to your page is an increasing function of the number of pages that have *already* linked to your page.
Second, the 'scale-free' nature of these power law functions has many implications. One is that *there is no 'average'*. Or, to be a little more precise: when something is distributed according to a power law, the 'average' (mean) is not a useful or informative statistic (unlike for a normal distribution [the 'bell-shaped curve']. Another is that power law curves are 'self-similar' -- wherever you look on a power law curve, the curve looks exactly the same (again, unlike a normal distribution, which has a different shape in different portions of the curve)
kennyFeb 10, 2003 at 7:30PM
steven den beste had a nice post on positive feedback wrt "american dominance," altho he acknowledges it's not unambiguously good.
PeteFeb 10, 2003 at 9:21PM
And come back tomorrow for the next episode of 'Kottke Does Neilsen'.
Leonid DelitsinFeb 11, 2003 at 3:38AM
>>average # of words per post
Actually the post size follows lognormal law:
http://anti.teneta.ru/research/images/msgsizelogx.gif
The average depends on the format, e.g. typical "post" is 10-15 words, i.e. about one sentence (sentence lengths is also distributed lognormally). The formats' sizes increase geometrically, so a "short story" is roughly about 10-30 "jokes", a "novel" is roughly 10-30 "short stories", etc.
http://anti.teneta.ru/research/images/prose_genres.gif
Michael BoyleFeb 11, 2003 at 1:04PM
I've been reading all of the articles on weblogs and the power laws, but they all seem to be built on an unsupported assumption: that linking to someone is a reliable and meaningful indicator of the reading habits of the link-from weblog.
I don't find any support for this except that originally when weblogs really got going, making a link on your own site was one of the only ways available to help yourself remember to go to the sites you preferred.
On the other hand, in 2003 there are many alternative methods - I use TinyTracker myself, but there are at least a half-dozen other ways of linking to often-read sites. My links are partially driven by my desire to read certain sites, but links also get there cause I'm polite, or because I want to reciprocate for someone who would consider my reciprocation (or lack thereof) significant, or old friends who nevertheless I don't read often, etc.
So what I would like to know is this: of heavily-trafficked sites, what proportion of their traffic comes from links from other weblogs? And, if that proportion is low, what do numbers of incoming links have to do with anything?
BTW, I'm also going to post this on my own site.
Broward HorneFeb 11, 2003 at 4:30PM
I'm surprised that nobody has mentioned anything about Ronald Coase or transaction costs yet.
http://www.sjsu.edu/faculty/watkins/coase.htm
snrFeb 15, 2003 at 8:52PM
"What does this tell us about computing and social lives? About collective action? What does this tell us about how people negotiate meaning or what they value in their interaction with others?
How does this help us build devices and applications that help people?"
Having just been gifted with the title "Network Information Messiah" on another site (hi Adam!), this resonates strongly with me.
Is there interest in creating a community devoted to discussing the practical implications of social networking, and maybe even designing & building some tools to test & exploit the concepts?
I can list several sites that have significant social networking content (SFI, Notre Dame, Smart Mobs off the top of my head, I'm sure others here can add to that). I've found none of them that has a section that's ideal for building a community. I guess the closest is Howard Rheingold's site, but that's his gig & I don't want to move in on him & take over the place.
As a start, I think a mailing list or Yahoo! community would fit the bill. Anybody interested?
s/n:r
This thread is closed to new comments. Thanks to everyone who responded.